
Pyspark와 Databricks : 클라우드 환경에서 빅데이터 처리 시작하기
1. 서론: Python과 Pandas의 한계, 그리고 PySpark & Databricks의 필요성
데이터의 홍수 속에서 데이터 분석가와 엔지니어에게 데이터 처리 능력은 핵심 역량이 되었다. Python의 Pandas 라이브러리는 데이터를 다루는 데 있어 매우 직관적이고 강력한 도구였다. 하지만 Pandas는 단일 서버의 메모리 안에서만 데이터를 처리할 수 있는 한계를 가졌다. 처리할 데이터의 크기가 서버 메모리를 초과하면, 작업은 불가능해지거나 극도로 느려졌다.
데이터의 규모가 수십, 수백 기가바이트를 넘어 테라바이트, 페타바이트 단위로 폭발적으로 증가하면서, 이러한 ‘단일 머신’ 환경의 한계는 빅데이터 분석과 처리에 가장 큰 걸림돌이 되었다. 이러한 문제를 해결하기 위해, 분산 컴퓨팅 환경에서 대규모 데이터를 처리하는 프레임워크인 Apache Spark가 등장했다.
그리고 Python 개발자들에게 익숙한 문법으로 Spark를 다룰 수 있게 해주는 도구가 바로 PySpark이다. PySpark는 Pandas의 한계를 극복하고, 수십, 수백 GB에 달하는 데이터도 분산된 환경에서 효율적으로 처리하는 무기가 된다. 이 PySpark를 클라우드 환경에서 손쉽게 다룰 수 있도록 돕는 플랫폼이 바로 Databricks이다. 본 포스팅에서는 PySpark의 핵심 원리를 파악하고, Databricks 환경에서 이를 어떻게 활용하는지 데이터 엔지니어의 관점에서 설명하고자 한다.
2. Databricks 환경 이해
Databricks는 Apache Spark 기반의 통합 분석 플랫폼(Unified Analytics Platform)이다. 데이터 과학자, 데이터 엔지니어, 머신러닝 엔지니어가 데이터 처리, 분석, 모델 개발 및 배포 작업을 한곳에서 수행하도록 설계되었다.
데이터 엔지니어에게 Databricks가 유용한 점은 다음과 같다.
- 관리형 Spark 클러스터: 복잡한 Spark 클러스터 설정 및 관리를 Databricks가 담당한다. 인프라 관리 부담 없이 데이터 처리 로직에 집중할 수 있다.
- 협업용 노트북 환경: 웹 기반 노트북으로 코드, 시각화, 설명을 통합한다. 팀원들과 실시간으로 협업하며 데이터를 탐색하고 파이프라인을 개발할 수 있다.
- 다양한 데이터 소스 연결: Azure Blob Storage, Azure Data Lake Storage, Azure SQL Database 등 다양한 Azure 데이터 서비스와 쉽게 연결하여 데이터를 읽고 쓸 수 있다.
- 확장성 및 효율성: 필요에 따라 클러스터 크기를 유연하게 조절하여, 대규모 데이터 처리 작업을 효율적으로 수행하고 비용을 최적화할 수 있다.
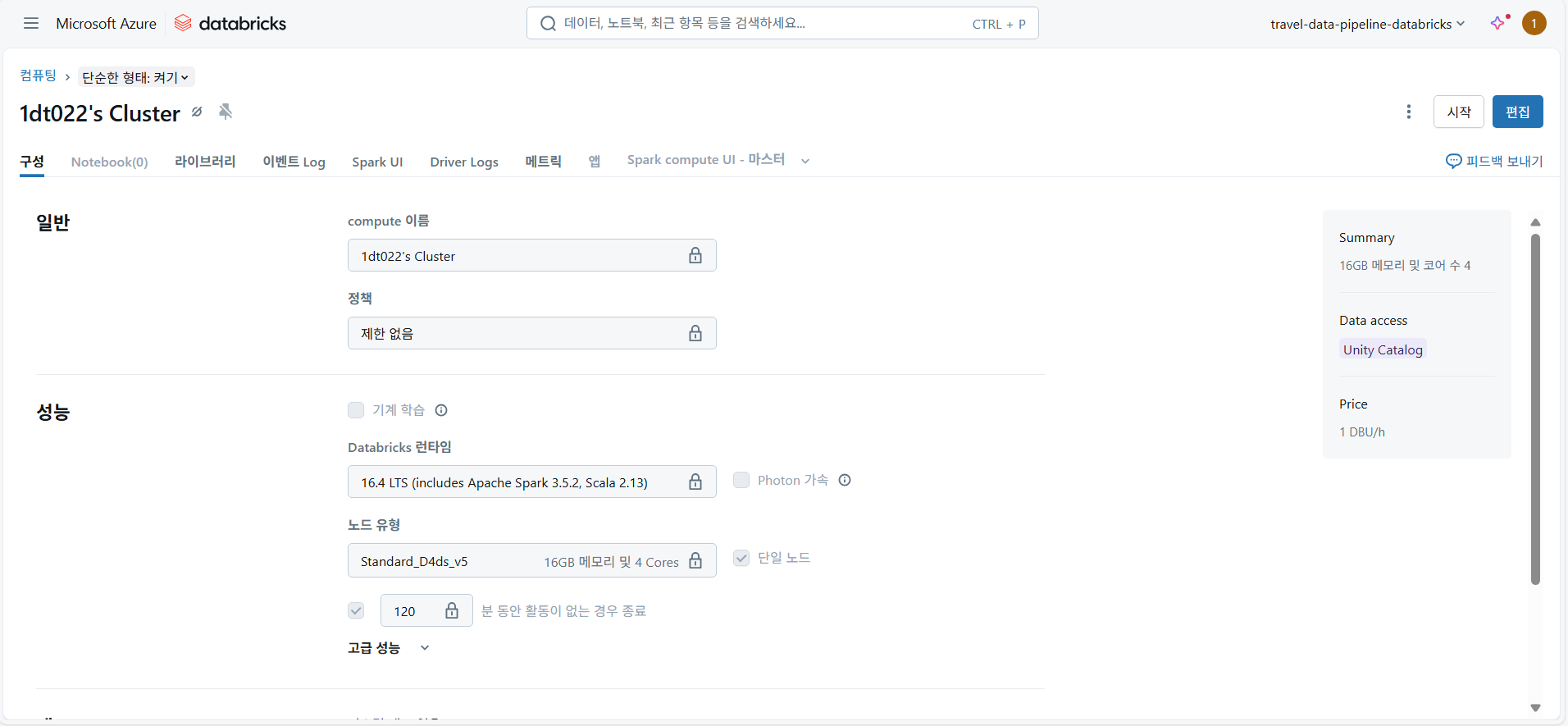
위 이미지는 Databricks 클러스터의 설정 화면이다. 여기서는 클러스터의 컴퓨팅 리소스(예: 16GB 메모리 및 4코어), 노드 유형, (Standard_D4ds_v5), 그리고 사용된 Databricks 런타임 버전(Apache Spark 3.5.2 포함) 을 확인할 수 있다. 이러한 관리형 클러스터는 데이터 엔지니어가 인프라 관리 부담 없이 데이터 처리 로직에만 집중 할 수 있게 하는 Databricks의 핵심 강점이다.
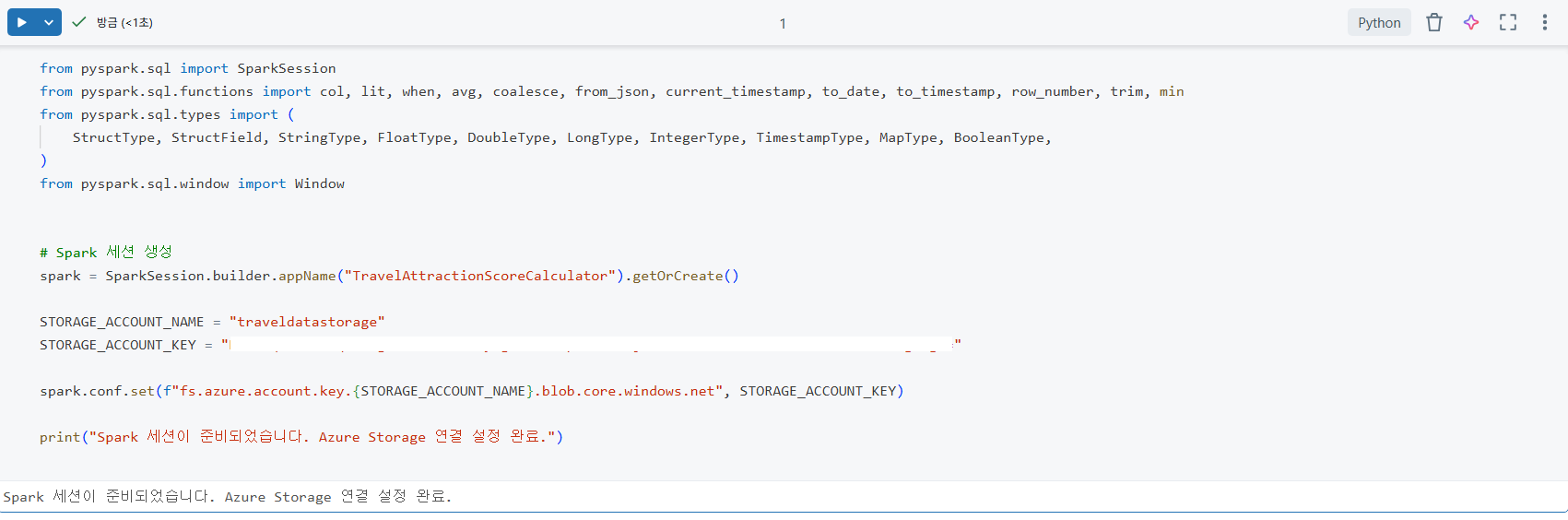
Databricks 노트북에서 Pyspark 작업을 시작하기 위한 SparkSession 설정과 Azure Blob Storage 연결 코드이다. SparkSession.builder를 통해 애플리케이션 이름을 정의하고 spark.conf.set을 사용하여 Azure Storage Account 키를 설정함으로써 데이터 레이크에 안전하게 접근 할 수 있는 환경을 구축했다. 이는 클라우드 환경에서 대규모 데이터를 로드하고 처리하기 위한 필수적인 초기 설정 과정이다.
3. PySpark 핵심 개념: Databricks 노트북
PySpark의 강력함을 온전히 활용하려면 몇 가지 핵심 개념을 파악해야 한다. 이 개념들은 Spark가 데이터를 어떻게 처리하고, 분산 환경을 어떻게 관리하는지 보여준다. Databricks 노트북 환경에서 이 개념들을 직접 실습하며 이해할 수 있다.
3.1 SparkSession: 분산 환경의 진입점
SparkSession은 PySpark의 모든 작업이 시작되는 진입점이다. Databricks 환경에서는 spark라는 이름으로 자동 생성되어 제공된다.
Databricks 환경에서는 SparkSession 객체가 spark라는 이름으로 자동으로 생성되어 제공된다. 따라서 별도의 설정 없이 바로 PySpark 코드를 시작할 수 있다.
3.2 DataFrame : 대규모 데이터를 위한 분산된 구조
DataFrame은 PySpark의 핵심 데이터 구조로, 대용량 데이터를 클러스터의 여러 노드에 분산하여 저장한다. 지연 연산(Lazy Evaluation)특성을 가진다
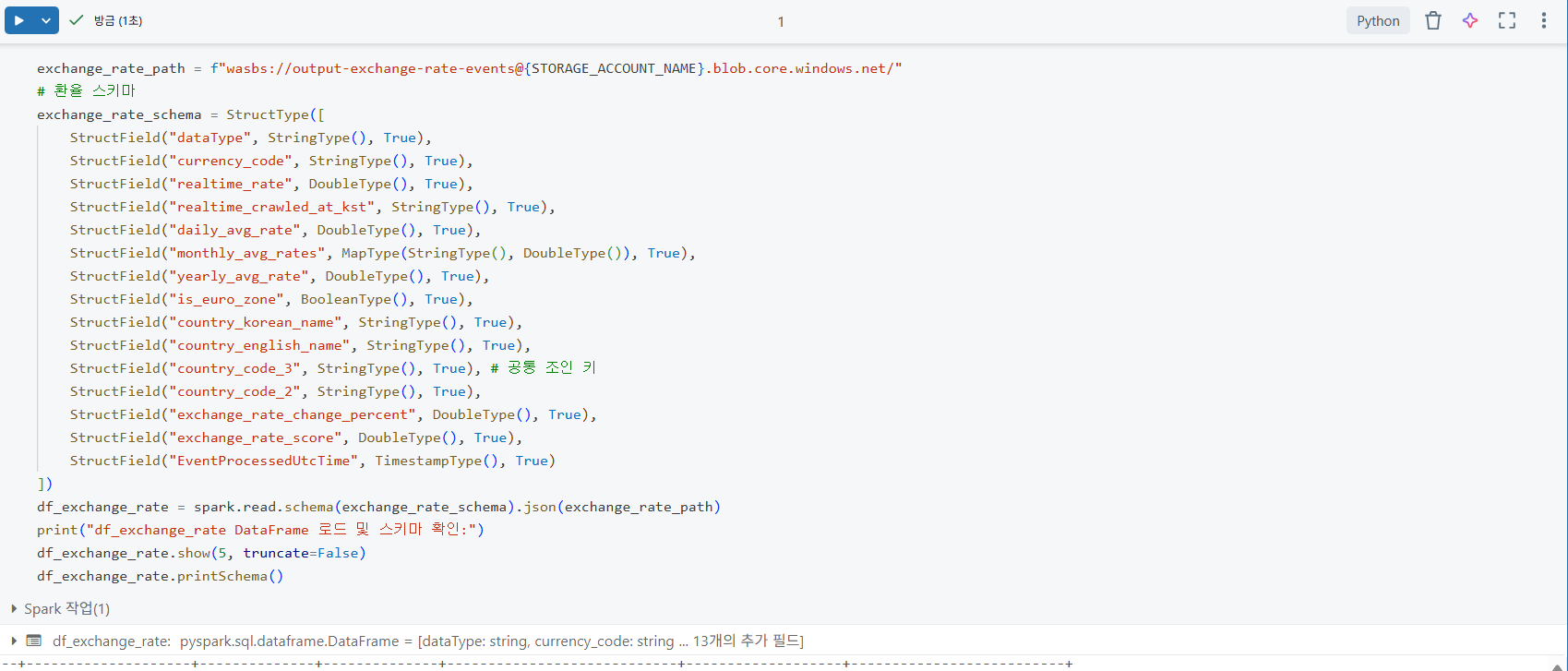
위 이미지는 exchange_rate_schema를 StrucType으로 명시적으로 정의하는 코드이다. 데이터 소스에서 오는 각 컬럼의 이름(dataType, currency_code등)과 정확한 데이터 타입(예:StringType, DoubleType)을 미리 지정함으로써, 데이터 로드 시 스키마 불일치로 인한 오류를 방지하고 데이터의 정합성을 확보한다. 이는 데이터 엔지니어링에서 데이터 품질 관리를 위한 중요한 단계이다.
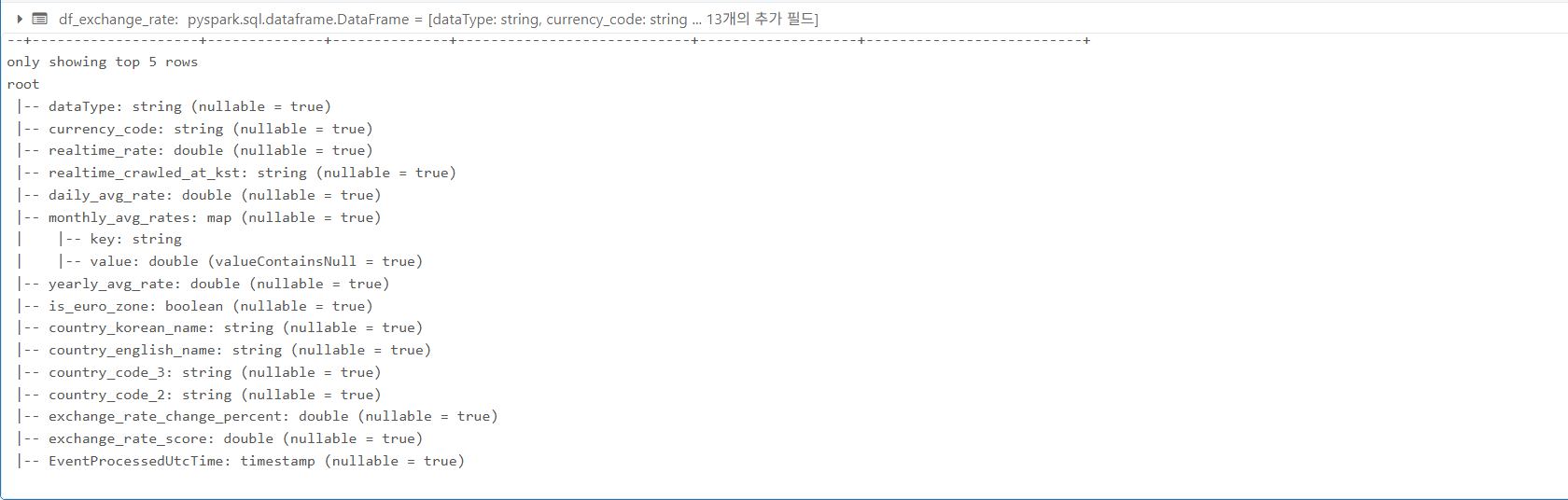
df.printSchema()명령을 실행한 결과이다. 정의된 스키마에 따라 DataFrame의 컬럼 이름, 데이터 타입, 그리고 Null 값 허용 여부가 계층적으로 출력된 모습니다. 이 출력은 데이터가 의도한 형식으로 정확히 로드되었는지 확인하고, 후속 데이터 처리 작업의 기반을 마련하는 데 필수적이다.
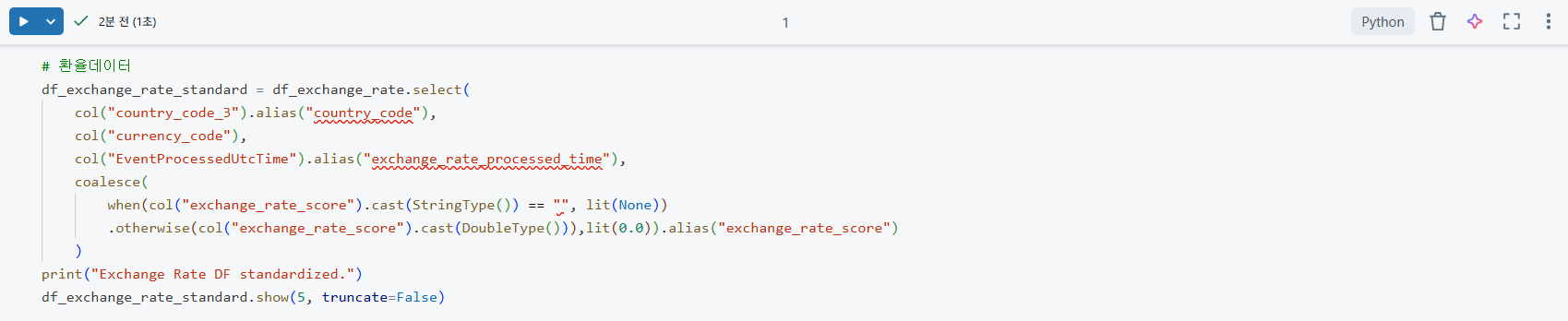
df_exchange_rate_standard DataFramd을 생성하는 코드이다. col().alias()를 사용하여 컬럼 이름을 표준화하고, when().otherwise().cast().coalesce()와 같은 함수들을 복합적으로 활용하여 데이터 타입을 정확히 맞추고 exchange_rate_score 컬럼의 빈 문자열("")이나 null값을 0.0으로 일괄 처리한다. 이는 데이터의 일관성을 확보하고 분석 오류를 방지하기 위한 중요한 정제 작업이다.
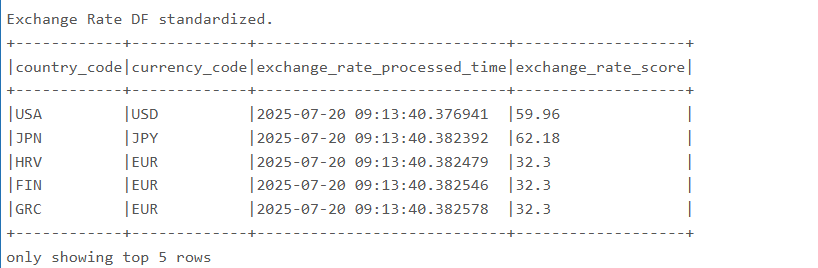
df_exchange_rate_standard.show(5, truncate=False)를 실행한 결과이다. 이전 단계에서 표준화하고 정제한 환율 데이터 DataFrame의 상위 5개 행을 보여준다. truncate=False 옵션을 사용하여 모든 컬럼의 내용을 잘림 없이 확인할 수 있다. 이는 데이터 정제 및 변환 작업이 의도대로 수행되었는지 시각적으로 검증하는 데 사용된다.
4. PySpark로 데이터 전처리 실습 (Databricks 활용)
이 섹션은 실제 데이터 엔지니어링 프로젝트에서 수행하는 핵심 전처리 작업들을 PySpark로 어떻게 구현하는지 보여준다.
4.1 최신 데이터 선택 : window 함수 활용
(3.2 DataFrame 섹션에서 이미 데이터 로드 및 초기 탐색에 대한 설명을 포함했으므로, 여기서는 해당 내용은 넘어간다.)
실시간 또는 준실시간으로 수집되는 데이터는 중복되거나 업데이트 될 수 있다. Window 함수를 활용하면 이러한 데이터 중 가장 최선 버전만을 선택하여 효율적으로 처리할 수 있다.

df_exchange_rate_latest DataFrame을 생성하는 코드이다. Window.partitionBy().orderBy().desc()와 row_number().over(window_spec)를 사용하여 각 통화 코드 및 국가 코드별로 가장 최신 exchange_rate_processed_time을 가진 레코드만을 선택한다. 이는 대규모 시계열 데이터에서 중복을 제거하고 최신 상태를 유지하기 위한 데이터 처리 기법이다.
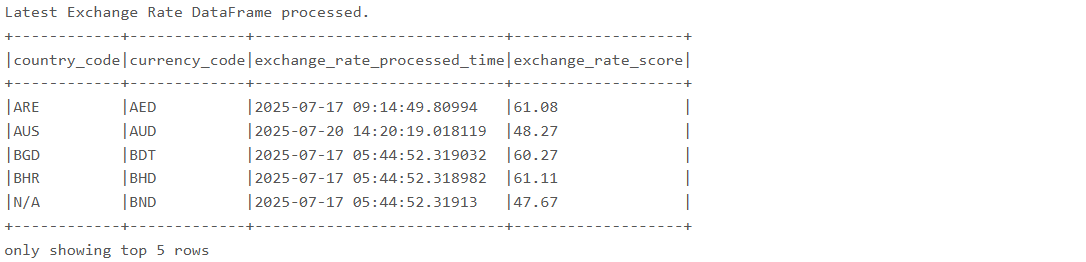
df_exchange_rate_latest.show(5, truncate=False)를 실행한 결과이다. Window 함수를 통해 각 그룹별로 최신 데이터만 선별된 DataFrame의 상위 5개 행을 보여준다. 이 출력은 복잡한 윈도우 함수가 실제 데이터에 어떻게 적용되었는지 시각적으로 확인하는 데 사용된다.
4.3 복잡한 데이터 통합 : 다중 조인 및 최종 정제
다양한 소스에서 표준화된 데이터를 모아 하나의 통합된 뷰를 만드는 것은 데이터 엔지니어의 중요한 역할이다. PySpark는 여러 DataFrame을 효율적으로 조인하고, 조인 후 발생할 수 있는 결측치를 일괄 처리하는 기능을 제공한다.
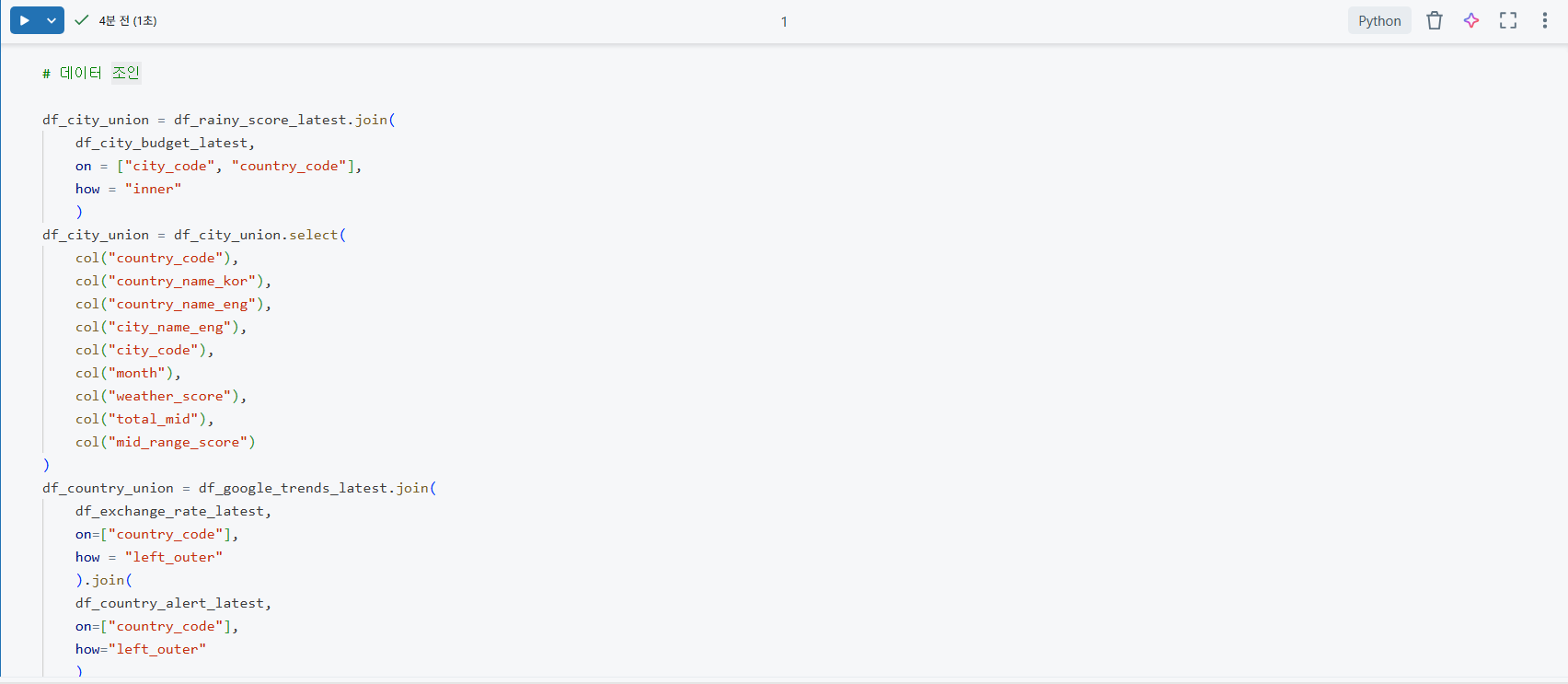
df_city_union, df_country_union, df_union, df_final_union과 같이 여러 DataFrame을 join() 메서드를 사용하여 순차적으로 통합하는 코드이다. inner 및 left_outer 조인을 적절히 활용하여 서로 다른 데이터셋(도시 정보, 국가 정보, 항공권 정보 등)을 공통 키(country_code, city_code, month)를 기준으로 연결한다. 이는 복잡한 비즈니스 로직을 위한 통합 데이터셋을 구축하는 핵심 과정이다.

df_final_union_kill_null DataFrame을 생성하는 코드이다. 여러 컬럼에서 발생할 수 있는 null 값들을 coalesce(col, lit(0.0)) 함수를 사용하여 0.0으로 일괄 대체하는 과정을 보여준다. 이는 조인 후 발생할 수 있는 결측치를 효과적으로 처리하여, 이후의 점수 계산 로직이나 분석 단계에서 오류를 방지하고 데이터의 견고성을 확보하는 데 필수적인 데이터 품질 관리 작업이다.
4.4 데이터 저장 : 파이프라인의 최종 단계
전처리된 데이터는 다음 분석 단계나 애플리케이션에서 활용될 수 있도록 적절한 형식과 위치에 저장된다. PySpark는 Delta Lake, Parquet 등 다양한 형식으로 데이터를 저장하는 기능을 제공한다.
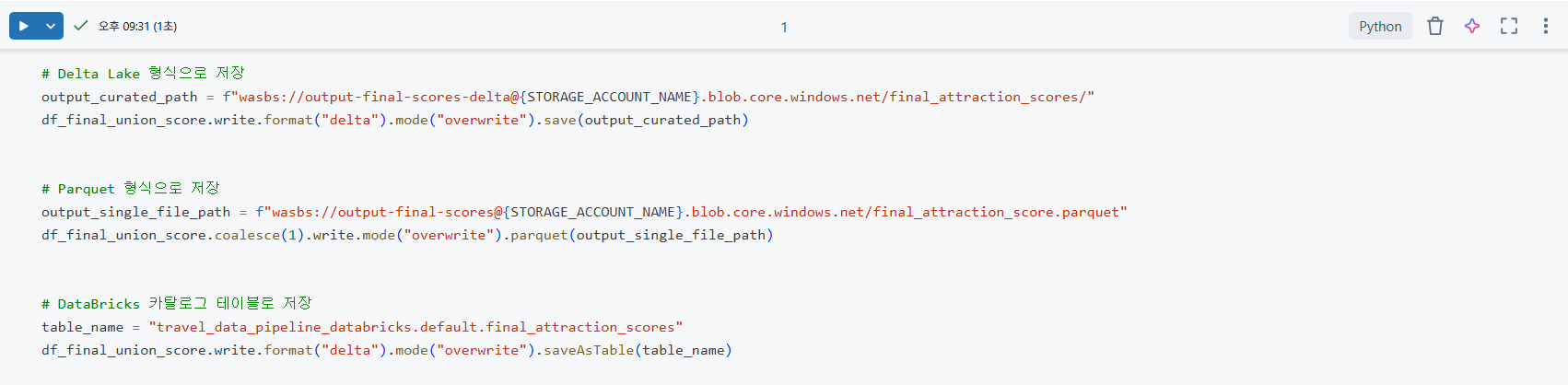
df_final_union_score DataFrame을 클라우드 저장소에 저장하는 세 가지 방법을 보여주는 코드이다.
Delta Lake형식 저장:write.format("delta").mode("overwrite").save()를 사용하여 데이터 레이크에 ACID 트랜잭션과 스키마 진화 등의 이점을 가진 Delta 형식으로 데이터를 저장한다.Parquet형식 저장:coalesce(1).write.mode("overwrite").parquet()를 사용하여 데이터를 Parquet 형식으로 저장하며,coalesce(1)로 단일 파일로 합쳐 효율적인 다운로드와 사용을 가능하게 한다.- Databricks 카탈로그 테이블로 저장:
saveAsTable()을 사용하여 Databricks 카탈로그에 관리형 테이블로 등록함으로써, SQL 분석가나 다른 사용자들이 쉽게 접근하고 활용할 수 있도록 한다.
5. 결론 : PySpark와 Databricks의 이해
이 포스팅을 통해 Python의 Pandas가 가진 단일 머신 환경의 한계를 이해했다. 그리고 대규모 데이터 처리의 필요성에 따라 Apache Spark와 그 Python API인 PySpark의 중요성을 파악했다. 또한, 클라우드 기반에서 PySpark를 가장 효율적으로 다룰 수 있는 통합 분석 플랫폼인 Databricks의 가치를 확인했다.
또, SparkSession, DataFrame, 카탈리스트 옵티마이저 와 같은 PySpark의 핵심 개념들이 어떻게 분산 환경에서 대규모 데이터를 처리하는지 원리적으로 이해했다. 나아가, Databricks 노트북 환경에서 데이터를 로드하고, select, filter, withColumn, join, groupBy와 같은 PySpark의 다양한 변환 메서드를 사용하여 데이터 정제, 변환, 통합, 집계 등 실제 데이터 전처리 작업을 수행했다. Window 함수를 활용한 최신 데이터 선별이나 coalesce를 통한 결측치 처리와 같이 데이터 품질을 확보하는 중요한 작업들도 직접 다루었다.
이러한 학습 경험은 데이터의 ‘규모’에 짓눌리지 않고, 데이터를 정제하고 변환하며 분석 가능한 형태로 제공하는 데이터 엔지니어의 핵심 역량을 강화하는 데 기여했다. PySpark와 Databricks에 대한 이해는 향후 더 복잡한 데이터 파이프라인을 설계하고 구축하는 데 든든한 기반이 될 것이다. 이 지식과 경험은 데이터 엔지니어로서 실무 문제 해결에 기여할 수 있는 나의 역량을 명확히 보여준다.