
[Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (2) : 데이터 수집 및 Google Trends HTTP 429 오류 해결
'[Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기' 시리즈의 다른 글들
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (4) : 클라우드 환경 운영 경험과 프로젝트 회고
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (3) : 아키텍처 변화와 데이터 처리 분석 (Stream Analytics ~ Databricks)
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (2) : 데이터 수집 및 Google Trends HTTP 429 오류 해결 (현재 글)
- [Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기(1) : 프로젝트 소개 및 아키텍처
지난 첫 번째 포스팅에서는 ‘나만의 최적 여행지 추천 시스템’ 프로젝트의 초기 비전과 데이터를 수집 및 처리하기 위한 전반적인 설계 방향을 소개했다. 하지만 구상과 현실은 달랐다. 프로젝트의 첫 번째 관문이자 가장 큰 도전은 바로 다양한 외부 데이터를 안정적으로 수집하는 과정에서 찾아왔다.
이 프로젝트를 구상하면서, 여러 데이터가 필요했지만 그중 가장 중요하다고 생각했던 데이터는 실시간 환율 데이터와 Google Trends 데이터였다. 실시간 환율을 대시보드에 보여주면 환율의 증감 추이를 직관적으로 알 수 있고, Google Trends(검색 데이터)의 추이를 따라 최근 검색량 변화를 파악할 수 있기 때문이었다.
하지만 Google Trends 데이터를 수집하기 위해서는 pytrends라는 비공식 Google Trends API를 사용해야 했는데, 이는 Google의 강력한 크롤링 방지 로직 때문에 쉽지 않았다. 특히 HTTP 429 Too Many Requests 에러는 데이터를 수집하는 데 큰 어려움을 주었다.
이번 포스팅에서는 프로젝트의 핵심 피처인 환율 및 Google Trends 데이터를 어떻게 수집했으며, 429 에러를 극복하기 위해 어떤 기술적 시도와 고민을 거쳐 최종적으로 해결했는지 상세히 다룰 것이다.
1. 데이터 수집 개요 및 환율 데이터 수집
우리 파이프라인은 Azure Function을 활용하여 다양한 외부 데이터 소스로부터 필요한 정보를 수집하는 것으로 시작한다. Azure Function은 서버리스 컴퓨팅 서비스로, 주기적인 실행이나 특정 이벤트에 반응하여 코드를 실행할 수 있어 데이터 수집 스크립트 실행에 매우 유용했다.
1.1 환율 데이터 수집 과정
프로젝트의 핵심 피처 중 하나인 환율 데이터는 현지 체감 비용을 계산하는 데 필수적이었다. 우리는 하나은행 웹사이트에서 실시간 환율 데이터를 크롤링하여 수집했다. 해당 웹사이트는 크롤링에 대한 방어가 거의 없는 편이어서, 예상과 달리 큰 기술적 문제 없이 5~10분 간격으로 안정적인 데이터 수집 파이프라인을 구축할 수 있었다.
 이 이미지는
이 이미지는 exchangeRateCrawler 함수가 로컬 환경에서 성공적으로 실행되어 환율 데이터를 수집하고 있음을 보여주는 로그 화면이다. Successfully saved exchange rates data to local file 및 Executed functions.exchangeRateCrawler' (Succeeded) 메시지를 통해 환율 데이터 수집 과정이 원활하게 진행되었음을 확인할 수 있다.
2. Google Trends 데이터 수집: HTTP 429 오류 해결
사용자에게 ‘지금 뜨는’ 여행지를 추천하기 위해 Google Trends 지수는 핵심적인 피처였다. Google Trends는 특정 기간 동안 여러 키워드(예: ‘미국 여행’, ‘일본 여행’)의 검색량을 0~100 스케일의 상대적 관심도 지수로 변환하여 제공한다. 이 지수는 실시간으로 변화하는 여행 트렌드를 파악하고 여행지 매력도 점수에 중요한 동적 요소를 추가하는 데 필수적이다.
하지만 Google Trends 데이터는 그 가치만큼이나 얻기 어려웠다. Google의 비공식 API(pytrends 라이브러리 사용)에 대한 엄격한 요청 제한(HTTP 429 Too Many Requests) 은 안정적인 데이터 수집에 가장 큰 장애물이었다.
 이 이미지는 Google Trends 데이터 수집 과정에서
이 이미지는 Google Trends 데이터 수집 과정에서 429 오류 해결 전략을 적용한 후, googleTrendsProcessor 함수가 로컬 환경에서 성공적으로 실행되고 있음을 보여주는 로그 화면이다. 여러 인스턴스가 병렬로 실행되고 각 요청이 성공(Succeeded)하는 것을 통해 분산 처리 아키텍처가 효과적으로 작동하고 있음을 확인할 수 있다.
2.1 Google Trends 데이터 수집 파이프라인 아키텍처
HTTP 429 오류를 근본적으로 해결하기 위해, 우리는 생산자-소비자(Producer-Consumer) 패턴 기반의 다중 인스턴스 분산 처리 아키텍처를 설계했다. 이 아키텍처는 단일 시스템 내에서의 한계를 벗어나 작업을 분할하고 병렬 처리함으로써 Google의 강력한 요청 제한을 우회하는 데 목적을 두었다.
Google Trends 데이터 수집을 위한 분산 처리 아키텍쳐
Producer (Azure Function App - Timer Trigger)
↓
Azure Queue Storage (메시지 큐)
↓
Consumer (Azure Function App - Queue Trigger)
↓
Crawler Logic (pytrends API 호출)
↓
Azure Event Hubs
각 주요 컴포넌트 간의 흐름은 다음과 같다.
- 생산자 (Producer) -
functions/google_trends_trigger.py:Timer Trigger기반으로 정해진 주기에 따라 Google Trends 크롤링 요청(국가 키워드 그룹)을 생성하고, 이를 Azure Queue Storage에 메시지로 보낸다.- 이 함수는 Google Trends API를 직접 호출하지 않아 타임아웃 및
429오류 발생 위험으로부터 자유로웠다.
- 메시지 큐 - Azure Queue Storage:
- 생산자가 발행한 크롤링 요청 메시지를 안전하게 보관한다. 이는 작업 부하를 분산하고, 후속 서비스의 안정성을 확보하는 중요한 역할을 했다.
- 소비자 (Consumer) -
functions/google_trends_processor.py:Queue Trigger를 통해 큐에 도착한 메시지를 감지하고, 개별 크롤링 요청을 처리한다.- 이 함수는 실제 Google Trends API 호출을 담당하는 로직(
data_sources/google_trends_crawler.py)을 호출한다. - Azure Functions의 자동 스케일링 기능을 활용하여 다수의 인스턴스로 병렬 처리함으로써, 서로 다른 아웃바운드 IP 주소로 요청을 분산하는 효과를 얻었다.
- 크롤링 로직 -
data_sources/google_trends_crawler.py- 소비자의 호출을 받아
pytrends라이브러리를 통해 Google Trends API를 실제로 호출하고, 정제된 데이터를 Azure Event Hubs로 전송한다.
- 소비자의 호출을 받아
- 이벤트 허브 - Azure Event Hubs
- 처리된 Google Trends 데이터를 실시간 스트림으로 수집하여 다음 분석 단계로 전달하는 중앙 허브 역할을 수행한다.
이러한 분산 처리 아키텍처는 단일 IP 주소에서의 과도한 요청을 회피하고, 각 작업의 실패 시 재시도 메커니즘을 통해 파이프라인의 견고성을 극대화하는 데 필수적이었다.
2.2 HTTP 429 오류 해결 상세 과정
Google Trends 데이터 수집 과정에서 빈번하게 429 오류가 발생하여 안정적인 데이터 수집이 불가능했다. Google의 강력한 요청 제한을 직접 확인할 수 있었다.
2.2.1 첫 번째 시도: time.sleep()을 이용한 요청 지연의 한계
가장 먼저 시도한 방법은 각 pytrends API 호출 사이에 time.sleep() 함수를 사용하여 순차적인 대기 시간을 두는 것이었다. 10초, 30초, 60초 등 점진적으로 대기시간을 늘려가며 요청 빈도를 낮추고자 했다.
그러나 이러한 단순 sleep 방식으로는 429 오류를 근본적으로 해결할 수 없었다. 동일한 IP 주소에서 발생하는 순차적인 요청은 Google의 감지 시스템을 우회할 수 없었고, 여전히 429 에러가 빈번하게 발생했다. 이 과정에서 상당한 시간을 허비하며 sleep의 한계를 명확히 깨달았다.
429 오류가 빈번히 발생하면서, 단순히 time.sleep()으로 요청 간격을 조절하는 방식으로는 근본적인 해결이 어렵다는 한계를 느꼈다. 로그를 통해 pytrends 라이브러리가 429 응답 시 pytrends.exceptions.TooManyRequestsError라는 특정 예외를 발생시킨다는 점을 명확히 확인했다. 이 예외 타입을 정확히 인지하면서, 이후 tenacity와 같은 라이브러리를 통한 더욱 정교하고 지능적인 예외 처리 및 재시도 전략의 필요성을 깨달았다.
2.2.2 두 번째 시도: tenacity 라이브러리 도입 및 문제 발생
단순 sleep만으로는 API 호출의 견고함을 확보할 수 없으므로, 실패한 요청에 대해 자동으로 재시도해주는 tenacity 라이브러리를 도입했다. tenacity는 오류 발생 시 정해진 시간만큼 기다렸다가 다시 시도하는 기능을 제공하며, 이때 기다리는 시간을 점진적으로 늘려가면서 재시도하여 서버에 무리를 주지 않고 오류 해결 기회를 준다.
tenacity 도입 후 초기 설정은 min=60초, max=600초의 대기 시간과 함께 requests.exceptions.RequestException 발생 시 재시도하도록 설정했다. 이전 단계에서 확인한 pytrends.exceptions.TooManyRequestsError를 tenacity가 인식하지 못했기에, 이를 tenacity의 retry_if_exception_type에 명시적으로 추가하여 429 오류를 완벽하게 감지하고 지능적으로 재시도하도록 수정했다.
# data_sources/retry_utils.py (재사용 가능한 유틸리티 모듈)
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
from requests.exceptions import RequestException
from pytrends.exceptions import ResponseError, TooManyRequestsError
import logging
def retry_log(retry_state):
logging.info(f"재시도 {retry_state.attempt_number}회: {retry_state.outcome.exception()} 발생. 다음 재시도는 {retry_state.next_action.sleep:.2f}초 후...")
def google_trends_api_retry():
return retry(
wait=wait_exponential(multiplier=1, min=600, max=3600), # 10분~1시간 지연
stop=stop_after_attempt(3), # 최대 3회 재시도
retry=retry_if_exception_type((RequestException, ResponseError, TooManyRequestsError)),
before_sleep=retry_log,
)
tenacity 도입과 정확한 예외 타입 지정으로 견고성은 확보되었으나, 여전히 단일 IP 주소에서 발생하는 모든 요청을 통제하는 방식으로는 Google의 강력한 429 제한을 완전히 뚫을 수 없었다. 모든 요청이 성공하는 것은 아니었고, Azure Function App에 올린다면 클라우드 환경에서 자동화 서비스를 안정적으로 유지할 수 없는 상황이었다.
2.2.3 세 번째 시도: 분산 처리 및 큐 기반 스케일링을 통한 해결
단일 시스템 내에서의 tenacity와 time.sleep만으로는 Google의 IP 기반 강력한 429 제한을 완전히 뚫기 어렵다는 것을 깨달았다. 결국, 근본적인 해결을 위해 Azure Functions의 분산 처리를 활용하기로 결정했다.
이 단계에서 Azure Queue Storage를 도입하여 googleTrendsTrigger (생산자)가 요청을 큐에 보내고, googleTrendsProcessor (소비자)가 큐 메시지를 받아 실제 API 호출을 수행하도록 역할을 분리했다. (이 아키텍처에 대한 상세 설명은 2.1 Google Trends 데이터 수집 파이프라인 아키텍처 섹션을 참고)
poison queue의 활용과 해결:- 큐를 통해 작업을 분할하고 처리하던 중, 처리되지 못한 메시지들이 Azure Queue Storage의
poison queue로 넘어가는 현상을 겪었다. 이는googleTrendsProcessor함수가 총 세 번의 재시도에도 불구하고 메시지 처리에 실패했음을 의미했다. - 이
poison queue는 초기에는 당황스러웠지만, 결국 실패한 메시지들을 격리하여 파이프라인의 안정성을 유지하는 중요한 메커니즘임을 이해하게 되었다.int64타입 직렬화 오류,EventHubOutputMessage사용법 오류,arg_name누락 등googleTrendsProcessor함수 자체의 오류들을 해결하면서poison queue로 넘어가는 메시지를 줄여갔다.
- 큐를 통해 작업을 분할하고 처리하던 중, 처리되지 못한 메시지들이 Azure Queue Storage의
- 최종 전략: IP 분산 및 전략적 지연:
- Azure Functions 다중 인스턴스: 큐에 쌓인 메시지가 많아지면 Azure Functions가 자동으로
googleTrendsProcessor함수 인스턴스를 여러 개 동시에 띄웠다. 이 각 인스턴스는 서로 다른 아웃바운드 IP 주소를 사용할 가능성이 높아, Google 입장에서는 요청이 다양한 출처에서 분산되어 들어오는 것처럼 보이게 하여429차단을 완화시켰다. - 인스턴스 간 API 요청 시작 지연:
functions/google_trends_processor.py함수가 큐 메시지를 받으면, 실제pytrendsAPI 호출 시작 전random.uniform(30, 60)초 동안 무작위로 기다리도록 했다. 이것은 여러 인스턴스가 동시에 뜨더라도 API 요청 시작 시점을 분산시켰다.# functions/google_trends_processor.py import time, random, logging # ... delay_seconds = random.uniform(30, 60) logging.info(f"Google Trends Processor : API 요청 전 {delay_seconds:.2f}초 지연 시작...") time.sleep(delay_seconds) # ... API 호출 로직 ... - API 호출 간 강제 지연:
data_sources/google_trends_crawler.py내부의pytrendsAPI 호출 직후,random.uniform(30, 60)초의 강제 지연 시간을 추가했다. 이 지연은 각 요청 간의 간격을 충분히 벌려 Google의 요청 빈도 감지 시스템을 효과적으로 우회하는 역할을 했다.# data_sources/google_trends_crawler.py (_fetch_trend_data_with_retry 함수 내) @google_trends_api_retry # tenacity 데코레이터 def _fetch_trend_data_with_retry(): # ... pytrends API 호출 ... time.sleep(random.uniform(30, 60)) # ...
- Azure Functions 다중 인스턴스: 큐에 쌓인 메시지가 많아지면 Azure Functions가 자동으로
2.2.4 최종 결과: 429 오류 해결
이러한 복합적이고 단계적인 전략 덕분에, 초기 테스트에서 발생했던 429 오류를 완전히 극복할 수 있었다. 이후 여러 차례의 테스트에서 단 한 번도 HTTP 429 TooManyRequests 오류 없이 모든 Google Trends API 요청이 성공적으로 완료되는 것을 확인했다. 이는 내가 설계하고 적용한 전략들이 Google의 엄격한 요청 제한을 효과적으로 우회하고 있음을 증명한다. 모든 61개 국가의 Google Trends 데이터가 안정적으로 수집되어 Event Hub로 전송되었다.
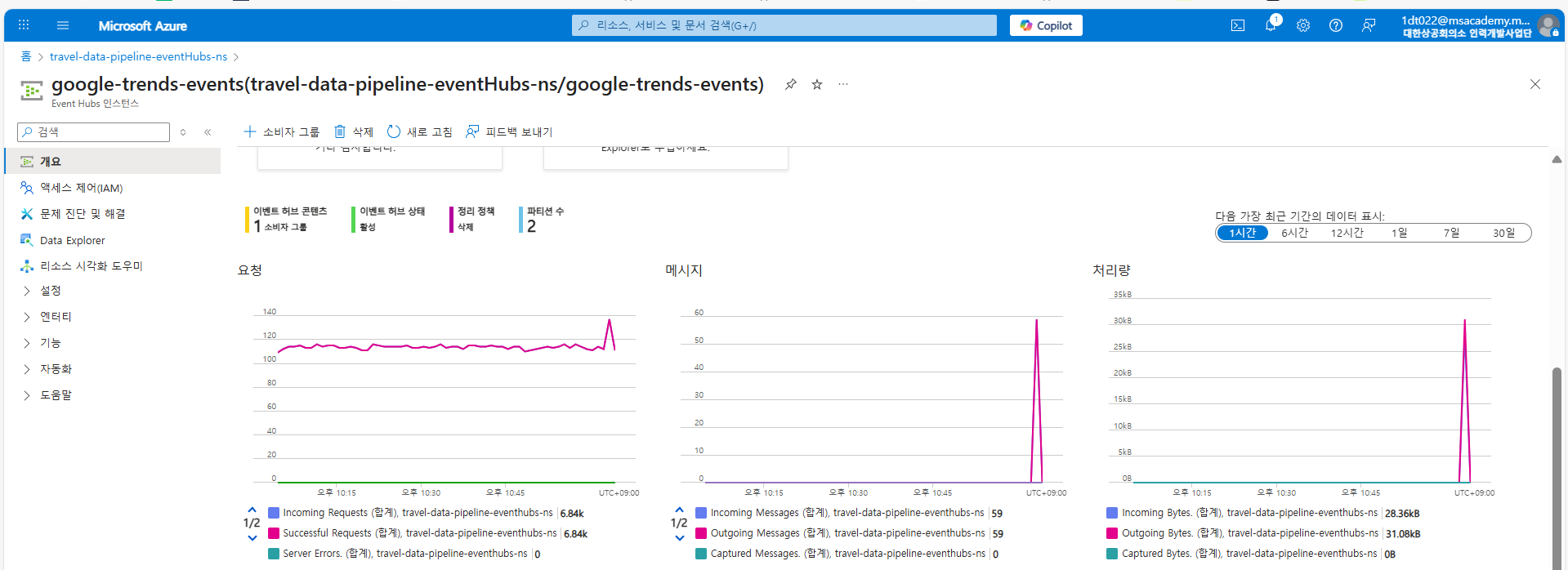
429 오류 해결 전략 적용 후, Google Trends 데이터가 Azure Event Hubs로 성공적으로 유입되고 있음을 보여주는 메트릭 화면이다. 그래프의 Incoming Requests와 Incoming Messages를 통해 데이터가 안정적으로 Event Hubs에 도착하고 있음을 확인할 수 있다.
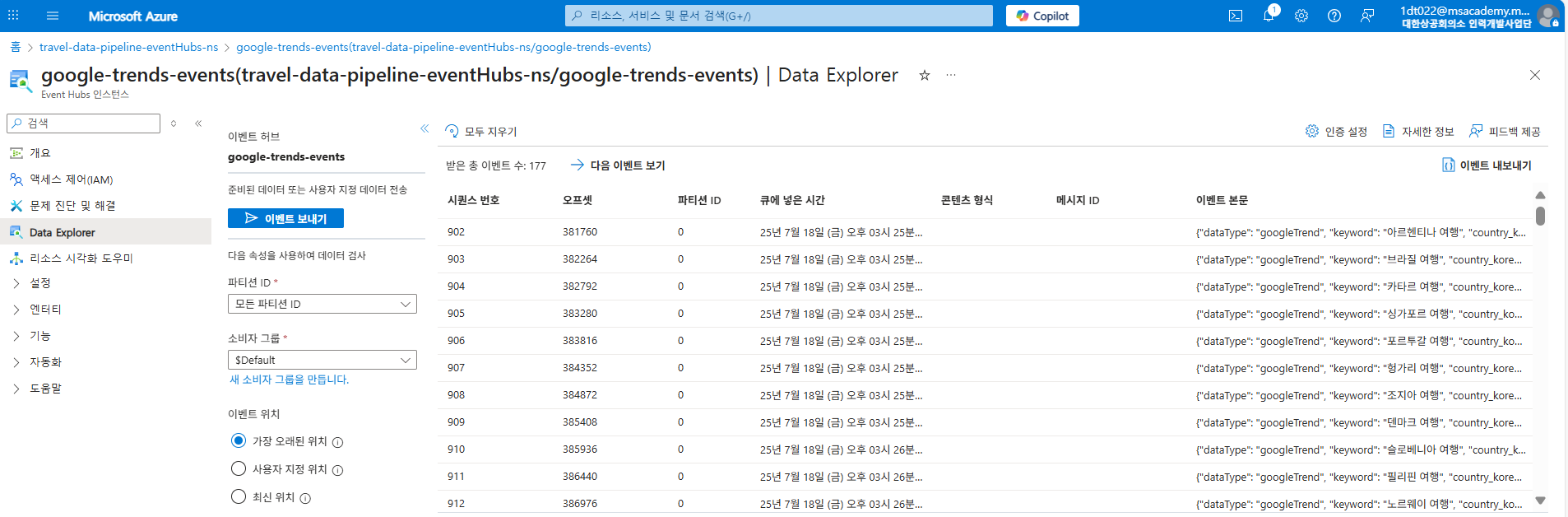 Event Hubs의 데이터 탐색기 화면으로, Google Trends 이벤트 데이터가 실제로 잘 저장되어 있음을 보여준다. 우측 ‘이벤트 본문’에서 JSON 형태로 수집된 트렌드 데이터의 일부를 확인할 수 있다.
Event Hubs의 데이터 탐색기 화면으로, Google Trends 이벤트 데이터가 실제로 잘 저장되어 있음을 보여준다. 우측 ‘이벤트 본문’에서 JSON 형태로 수집된 트렌드 데이터의 일부를 확인할 수 있다.
3. pytrends 환경 설정 및 핵심 크롤링 로직 구현 (google_trends_crawler.py)
pytrends를 사용하기 위해서는 프로젝트의 의존성 목록에 추가해야 한다.
# requirements.txt
pytrends
pandas
# 기타 필요한 라이브러리
get_integrated_travel_trends 함수는 pytrends를 활용하여 전 세계 국가별 ‘여행’ 관련 키워드의 Google Trend 데이터를 수집하고, 이를 기반으로 각 국가의 관심도 ‘성장률’과 ‘현재 관심도’를 복합적으로 계산하여 최종적인 ‘통합 트렌드 지수’를 산출한다. 이 과정은 여러 키워드를 함께 조회할 때 발생할 수 있는 상대적 스케일링 문제를 해결하기 위한 방법을 포함한다.
# google_trends_crawler.py
import logging
import datetime
import json
import os
import azure.functions as func
from pytrends.request import TrendReq
import pandas as pd
import time
import pytz
# 여러 키워드를 비교하고 '성장률' 기반의 트렌드 지수를 계산하는 핵심 함수
def get_integrated_travel_trends(
country_keywords: dict, timeframe: str = "today 3-m", geo: str = "KR"
) -> list:
# Google Trends 연결 도구 초기화. 한국어(ko-KR) 인터페이스와 한국 시간대(tz=540분 = GMT+9) 설정
pytrends_connector = TrendReq(hl="ko-KR", tz=540)
# ... (생략된 코드) ...
이후 get_integrated_travel_trends 함수 내부에 트렌드 지수 계산 로직이 포함되며, 이는 다음 포스팅에서 Databricks의 데이터 처리 부분과 함께 더 자세히 설명할 예정이다.
4. 데이터 수집의 다음 단계: Azure Event Hubs로의 전송
Azure Functions를 통해 안정적으로 수집된 환율 및 Google Trends 데이터는 Azure Event Hubs로 전송된다. Event Hubs는 우리 파이프라인의 중앙 스트리밍 데이터 허브 역할을 수행하며, 대규모 이벤트를 안정적으로 수집하고 다음 처리 단계로 효율적으로 전달하는 핵심 구성 요소이다.
Event Hubs 덕분에 우리는 다양한 데이터 소스로부터 들어오는 이기종 데이터를 한곳으로 모아, 복잡한 실시간 처리 없이 다음 단계로 신속하게 넘길 수 있었다.
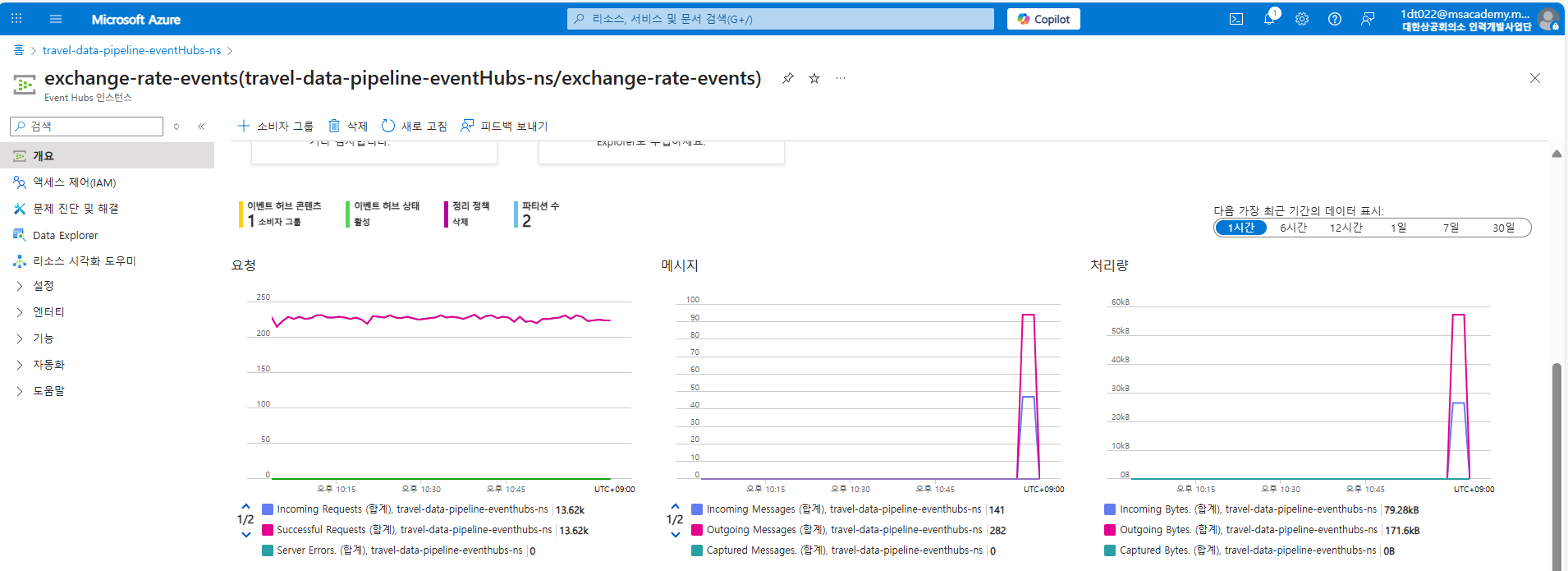
환율 데이터가 Azure Event Hubs로 성공적으로 유입되고 있음을 보여주는 메트릭 화면이다. Google Trends와 마찬가지로 Incoming Requests와 Incoming Messages 그래프를 통해 환율 데이터 스트림이 안정적으로 Event Hubs로 전송되고 있음을 확인할 수 있다.
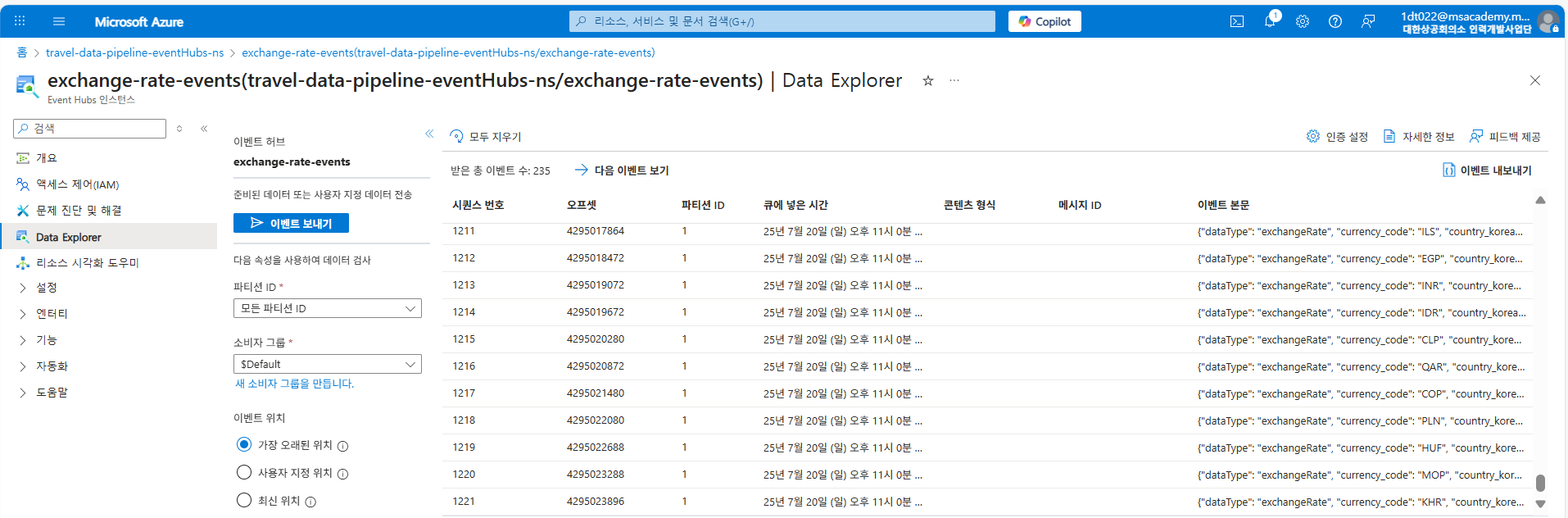
Event Hubs의 데이터 탐색기 화면으로, 환율 이벤트 데이터가 실제로 Event Hubs에 저장되어 있음을 보여준다. 우측 ‘이벤트 본문’에서 크롤링된 환율 데이터의 상세 내용을 확인할 수 있다.
5. 앞으로의 이야기
데이터 수집 단계에서 가장 큰 난관이었던 Google Trends 429 오류를 성공적으로 극복하고, 필요한 모든 데이터를 안정적으로 Event Hubs에 모을 수 있었다. 하지만 프로젝트는 여기서 멈추지 않는다. 다음 포스팅에서는 초기 아키텍처 구상과 달리 데이터 처리 단계에서 어떤 문제에 직면했으며, Stream Analytics의 역할이 어떻게 재조정되었고 Azure Databricks가 복잡한 데이터 통합과 분석의 핵심적인 역할을 맡게 되었는지에 대한 이야기를 이어갈 것이다.







