
[Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (3) : 아키텍처 변화와 데이터 처리 분석 (Stream Analytics ~ Databricks)
'[Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기' 시리즈의 다른 글들
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (4) : 클라우드 환경 운영 경험과 프로젝트 회고
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (3) : 아키텍처 변화와 데이터 처리 분석 (Stream Analytics ~ Databricks) (현재 글)
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (2) : 데이터 수집 및 Google Trends HTTP 429 오류 해결
- [Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기(1) : 프로젝트 소개 및 아키텍처
데이터 수집 단계에서 Google Trends HTTP 429 오류를 해결하고 필요한 데이터를 안정적으로 Azure Event Hubs에 모았다. 이제 수집된 원시 데이터를 가공하고 통합하여 ‘여행지 매력도 점수’를 산출하는 단계로 넘어왔다.
첫 번째 포스팅에서 언급했듯이, 초기에는 모든 복잡한 데이터 조인과 계산을 Azure Stream Analytics(이하 ASA)에서 처리할 계획이었다. 하지만 실제 구현 과정에서 예상치 못한 문제에 직면했고, 이는 아키텍처의 핵심적인 변화를 가져왔다. 이번 포스팅에서는 초기 구상과 달리 데이터 처리 단계에서 어떤 문제에 직면했으며, Stream Analytics의 역할이 어떻게 재조정되었고, Azure Databricks가 복잡한 데이터 통합 및 분석의 주요 구성 요소가 되었는지 상세히 다룰 것이다.
1. 최종 시스템 아키텍처: 진화된 데이터 파이프라인
데이터 수집 단계의 안정화 이후, 초기 구상을 보완하고 실제 데이터 처리의 복잡성을 해결하기 위해 아키텍처를 변경했다. 다음은 최종적으로 구현된 ‘나만의 최적 여행지 추천 시스템’의 End-to-End 데이터 파이프라인 아키텍처이다.
.png)
위 다이어그램에서 볼 수 있듯이, 데이터는 Function App을 통해 수집되어 Event Hubs로 전달된다. 이어서 Stream Analytics의 역할이 조정되었고, Azure Blob Storage와 Azure Databricks가 데이터 저장 및 복잡한 분석을 담당하게 되었다. 마지막으로 Power BI를 통해 최종 결과가 시각화된다.
2. Azure Stream Analytics (ASA)의 역할: 한계와 대응
Azure Event Hubs에 모인 대규모 스트림 데이터를 처리하기 위해 우리는 Azure Stream Analytics를 사용했다. 초기 계획은 ASA에서 실시간 환율, 구글 트렌드, 날씨 등 모든 데이터셋을 조인하고 복잡한 계산을 수행하여 최종 ‘매력도 점수’를 직접 산출한 뒤 Power BI로 넘기는 것이었다.
2.1 초기 구상의 한계점
하지만 실제 데이터를 다루면서 ASA의 한계를 확인했다.
-
복잡한 조인 및 다양한 세분성 데이터 처리의 제약: 우리 프로젝트는 월별/도시별/국가별 데이터와 같은 주기성 데이터와 실시간 환율 및 트렌드 데이터를 복합적으로 조인해야 했다. 또한, 각 데이터셋은 서로 다른 시간적, 공간적 세분성을 가지고 있었다. ASA는 스트림 데이터를 실시간으로 처리하는 데는 강점을 가졌지만, 이처럼 다양한 세분성을 가진 여러 데이터셋을 복합적으로 조인하고, 다단계 조인 및 정교한 시간 윈도우(Window) 함수를 적용하는 데는 기능적 제약이 있었다. SQL과 유사한 쿼리 언어를 사용하지만, 배치 처리 환경에서 제공되는 다양한 ETL(Extract, Transform, Load) 기능에는 미치지 못했다.
-
재처리 및 디버깅의 어려움: 실시간 스트림 데이터의 특성상, 쿼리 로직에 오류가 발생하거나 데이터 재처리가 필요할 경우 디버깅 및 재실행이 쉽지 않았다. 모든 로직이 ASA 쿼리에 집중될 경우, 개발 및 유지보수 효율이 저하될 것이라고 판단했다.
이러한 한계점들을 바탕으로, ASA의 역할을 재조정하고 더 유연하고 강력한 배치 처리 환경이 필요하다고 판단했다.
2.2 Stream Analytics의 역할 재정의
한계점을 고려하여 Stream Analytics의 역할을 다음과 같이 두 가지 주요 기능으로 재정의하여 파이프라인의 효율성과 견고성을 높였다.
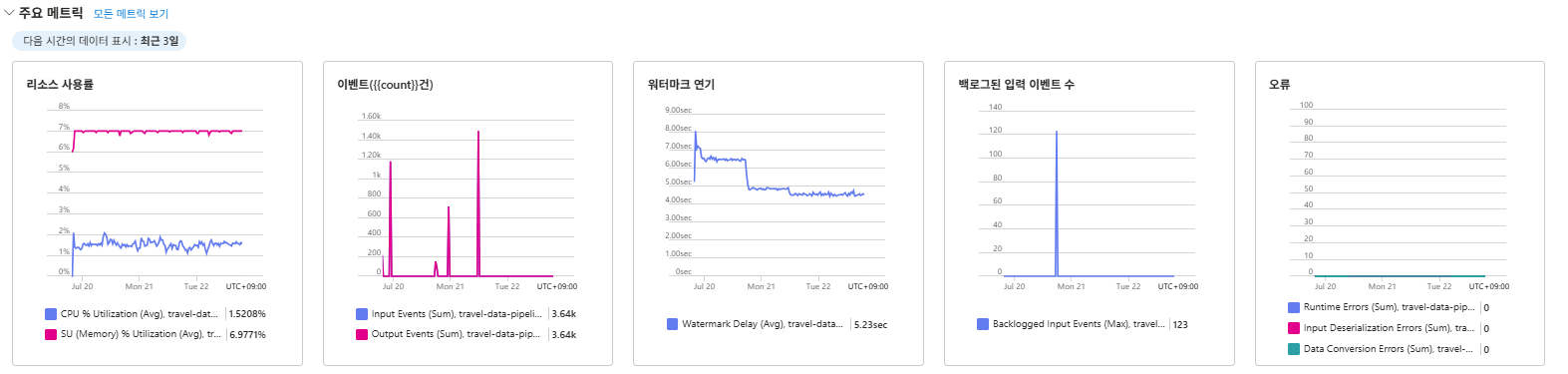
위 이미지는 Stream Analytics 작업의 전반적인 메트릭을 보여준다. Event Hubs로부터 데이터가 성공적으로 유입되고(Input Events), Blob Storage와 Power BI 출력으로 데이터가 흐르고(Output Events) 있음을 확인할 수 있다.
2.2.1 원시 데이터 저장(데이터 레이크 구성)
- Stream Analytics를 통해 Event Hubs에서 유입되는 모든 원시 데이터를 Azure Blob Storage로 전달하여 저장했다. Blob Storage는 비용 효율적인 대규모 저장소로, 데이터 레이크의 원시(Raw) 레이어 역할을 수행한다. 이는 향후 더 복잡한 배치 처리를 위한 기반을 마련했다.
- Stream Analytics 쿼리 예시 (원시 데이터 전달)
-- Stream Analytics 쿼리 예시 (모든 데이터를 Blob Storage로 전달)
SELECT
* -- 모든 컬럼을 선택하여 원시 데이터를 그대로 저장
INTO
OutputBlobStorage -- Blob Storage 출력 별칭
FROM
InputEventHub -- Event Hub 입력 별칭
2.2.2 실시간 데이터 스트리밍 (Power BI 연동)
- 환율, 날씨와 같이 즉각적인 변화를 시각화해야 하는 일부 데이터는 Stream Analytics에서 간단히 정제하여 Power BI 대시보드로 직접 스트리밍했다. 이를 통해 실시간 환율 변동이나 현재 날씨와 같은 지표를 대시보드에서 즉시 확인할 수 있었다. 이는 ASA의 실시간 스트림 처리 강점을 활용한 방안이었다.
- Stream Analytics 쿼리 예시 (실시간 지표 Power BI 스트리밍)
-- Stream Analytics 쿼리 예시 (날씨 데이터 정제 후 Power BI로 스트리밍)
SELECT
TRY_CAST(timestamp AS DATETIME) AS 측정시각, city AS 도시,
weather_desc AS 날씨상태, TRY_CAST(temp AS FLOAT) AS 현재기온,
TRY_CAST(humidity AS FLOAT) AS 습도
INTO
OutputPowerBI -- Power BI 출력 별칭
FROM
WeatherDataStream -- 날씨 데이터 스트림 입력 WHERE weather_desc IS NOT NULL
이처럼 Stream Analytics의 역할을 재조정하여, 각 서비스의 강점을 활용하고 데이터 파이프라인의 효율성과 견고성을 높였다.
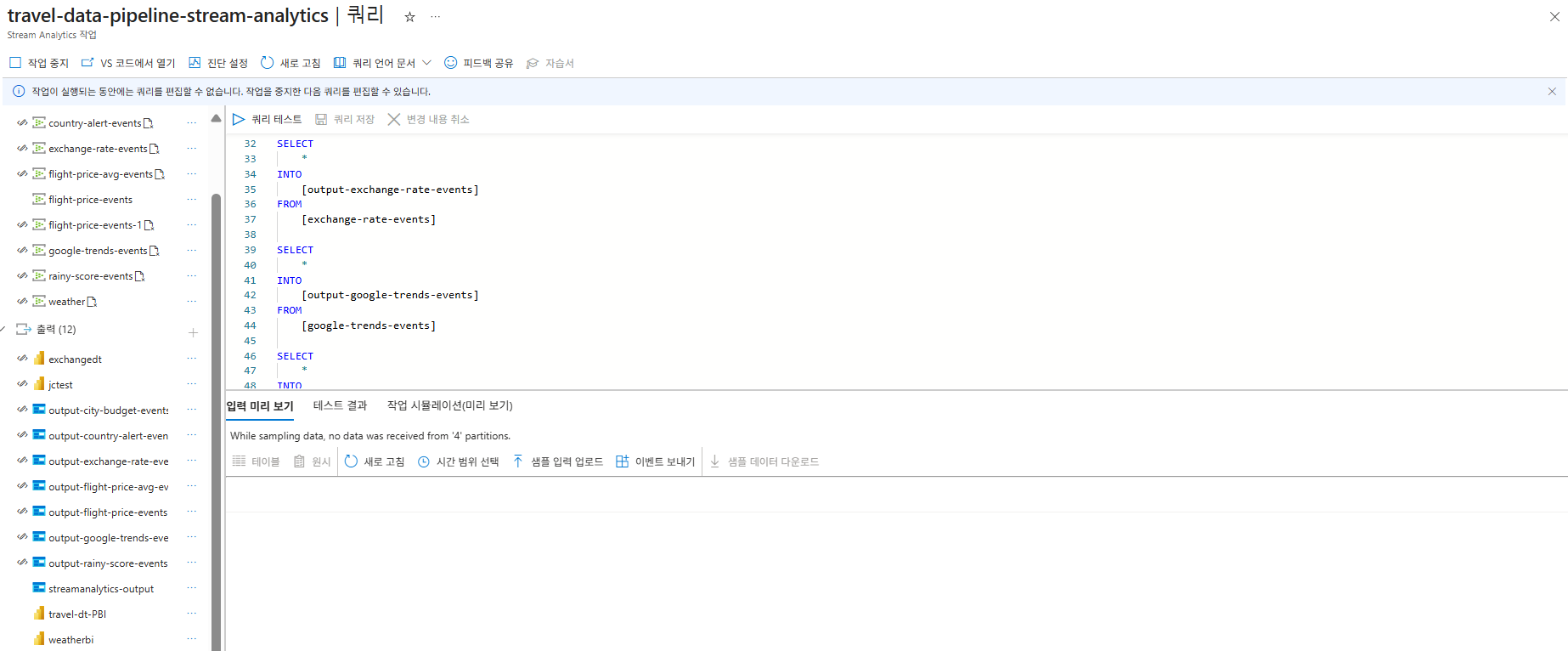
초기에는 복잡한 조인을 시도했지만, 결국 Stream Analytics의 쿼리는 위와 같이 각 Event Hub의 원시 데이터를 해당하는 Blob Storage 컨테이너로 전달하는 단순한 역할에 집중하게 되었다. 이는 데이터의 복합적인 가공은 Databricks에 맡기고, ASA는 실시간 데이터 스트리밍에 최적화된 기능을 활용하기 위함이었다. Stream Analytics의 입력은 Event Hubs로 설정하여, 다양한 소스에서 수집된 스트림 데이터를 실시간으로 받아들였다. 출력은 재정의된 역할에 따라 Azure Blob Storage와 Power BI 대시보드로 구성했다. 이는 원시 데이터를 효율적으로 저장하고, 실시간 지표를 즉시 시각화하기 위함이었다.
3. Azure Blob Storage: 대규모 데이터 저장을 위한 데이터 레이크
Stream Analytics를 통해 전달되거나 다른 경로로 적재된 데이터는 Azure Blob Storage에 저장된다. 이곳은 우리 파이프라인의 모든 데이터를 위한 중앙 저장소이자, 대규모 데이터 레이크의 주요 구성 요소이다.
- 비용 효율적인 대용량 저장소: 정형, 비정형, 반정형 데이터를 모두 저장할 수 있으며, 페타바이트 규모의 데이터를 저렴한 비용으로 보관한다.
- Databricks의 데이터 소스: Blob Storage에 저장된 데이터는 Azure Databricks가 데이터를 가져와 고급 분석 및 변환을 수행하는 주된 소스가 된다.
- Delta Lake 테이블 활용: 이 Blob Storage는 Azure Databricks에서 Delta Lake 테이블로 활용된다. Delta Lake는 저장된 데이터에 ACID(원자성, 일관성, 고립성, 내구성) 트랜잭션을 제공하여 데이터의 무결성을 보장하고, 스키마 적용 및 변경, 시간 여행(Time Travel)과 같은 고급 기능을 통해 효율적인 데이터 관리를 가능하게 했다.
Blob Storage를 중심으로 데이터 레이크를 구성하여, 유연한 데이터 관리와 확장성을 확보했다.
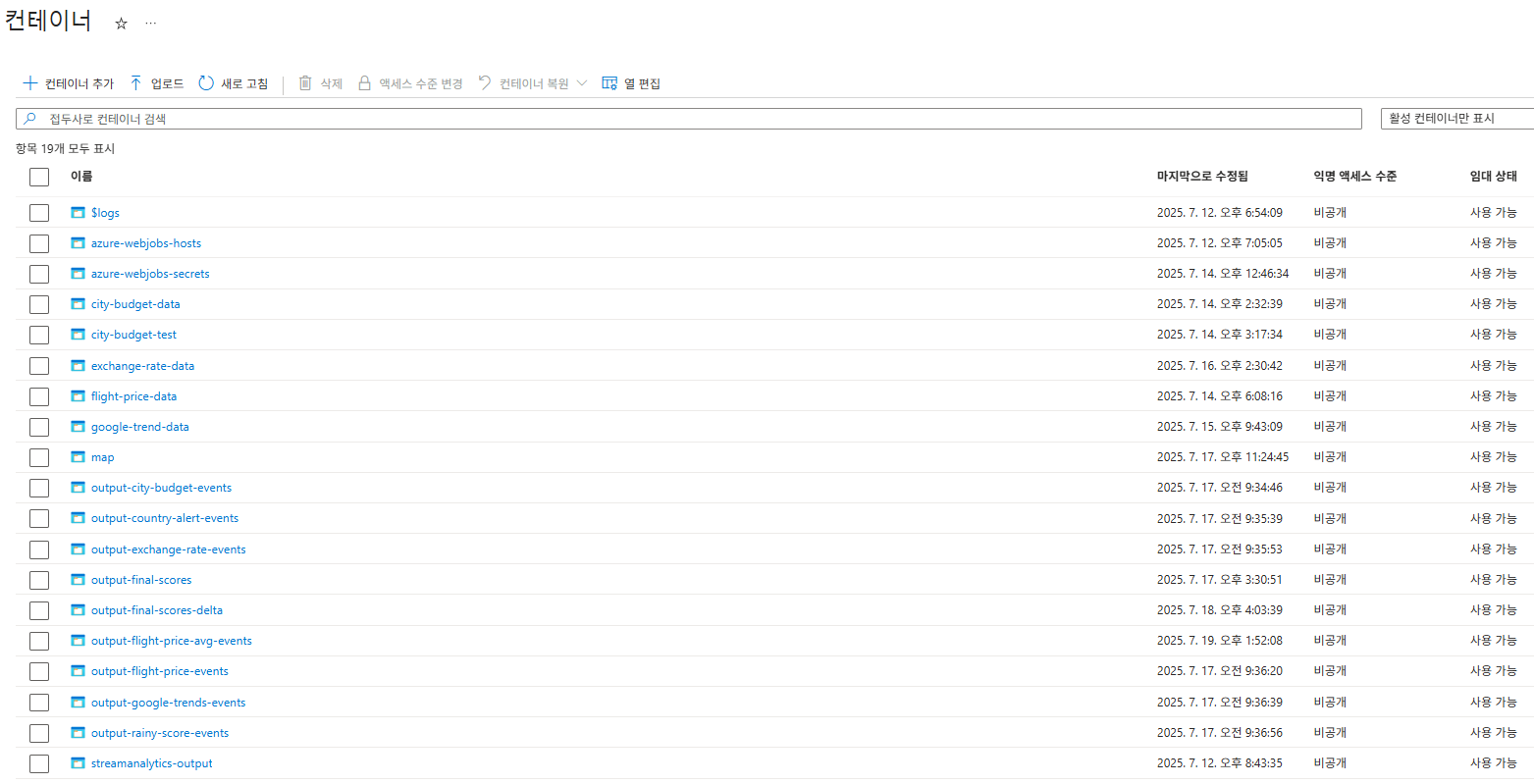
위 이미지는 Stream Analytics를 통해 전달된 데이터가 Azure Blob Storage에 파일 형태로 저장된 모습을 보여준다. 이는 Databricks에서 데이터를 읽어오는 주요 소스가 되었다.
4. Azure Databricks: 복잡한 배치 처리 및 데이터 통합
Azure Stream Analytics에서 수행하기 어려웠던 모든 복잡한 배치 데이터 처리와 통합 로직은 Azure Databricks에서 PySpark를 사용하여 수행했다. Databricks는 Apache Spark 기반의 분석 플랫폼으로, 대규모 데이터 처리와 머신러닝 워크로드에 최적화된 환경을 제공한다.
하지만 Databricks로 데이터를 옮긴 후에도 새로운 문제에 직면했다. 수집된 원시 데이터의 실제 상태를 확인하면서 데이터 통합 과정의 복잡성을 직접 경험하게 되었다. Blob Storage에서 JSON 형식의 원시 데이터를 읽어들이는 순간, 데이터 간 조인이 원활하지 않음을 확인했다.
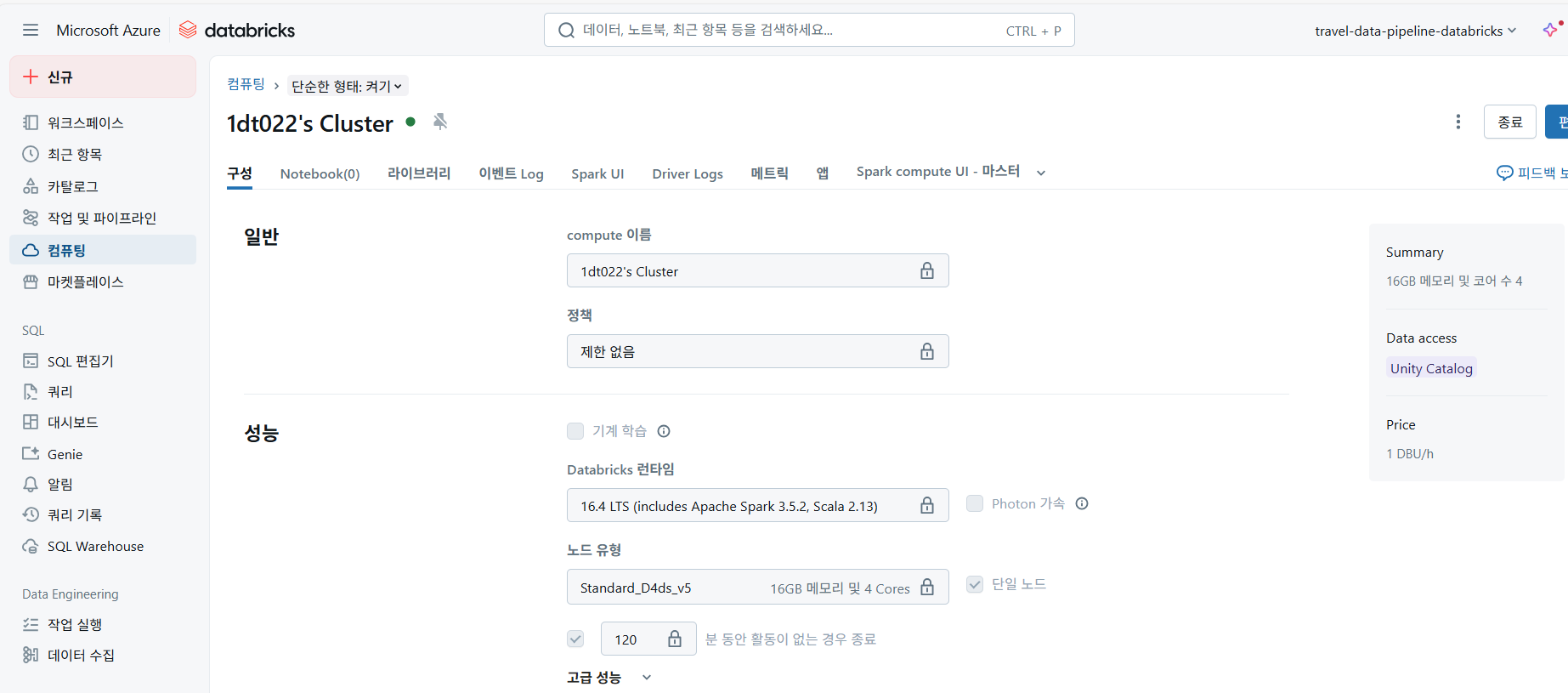
우리는 대규모 데이터 처리를 위해 위와 같은 구성의 Azure Databricks 클러스터를 사용했다.
4.1 원시 데이터의 품질 문제 파악
우리가 마주한 원시 데이터의 가장 큰 문제점들은 다음과 같았다.
- 컬럼명 불일치 및 중구난방: 각 데이터 소스별로 컬럼명이 제각각이었다. 예를 들어, 어떤 데이터는 국가를 ‘USA’로, 어떤 데이터는 ‘미국’으로, 또 다른 데이터는 ‘US’나 특정 국가 코드로 부르는 식이었다. 도시명도 마찬가지였다. 이는 데이터를 통합하기 위한 기본적인 조인조차 어렵게 만들었다.
- 타입 캐스팅 오류: 숫자여야 할 값이 문자열로 들어오거나, 예상치 못한 타입으로 저장된 경우가 많았다. 이는 계산을 불가능하게 만들었다.
- 높은 결측치 비율: 일부 데이터 소스는 특정 시점이나 특정 항목에 대한 데이터가 아예 누락되어 있었다.
이러한 문제들로 인해, 단순히 Inner Join을 시도하면 전체 행 수가 1/4 토막 나는 심각한 데이터 손실이 발생했다. 이는 우리가 기대했던 풍부한 통합 데이터를 얻을 수 없음을 의미했다.
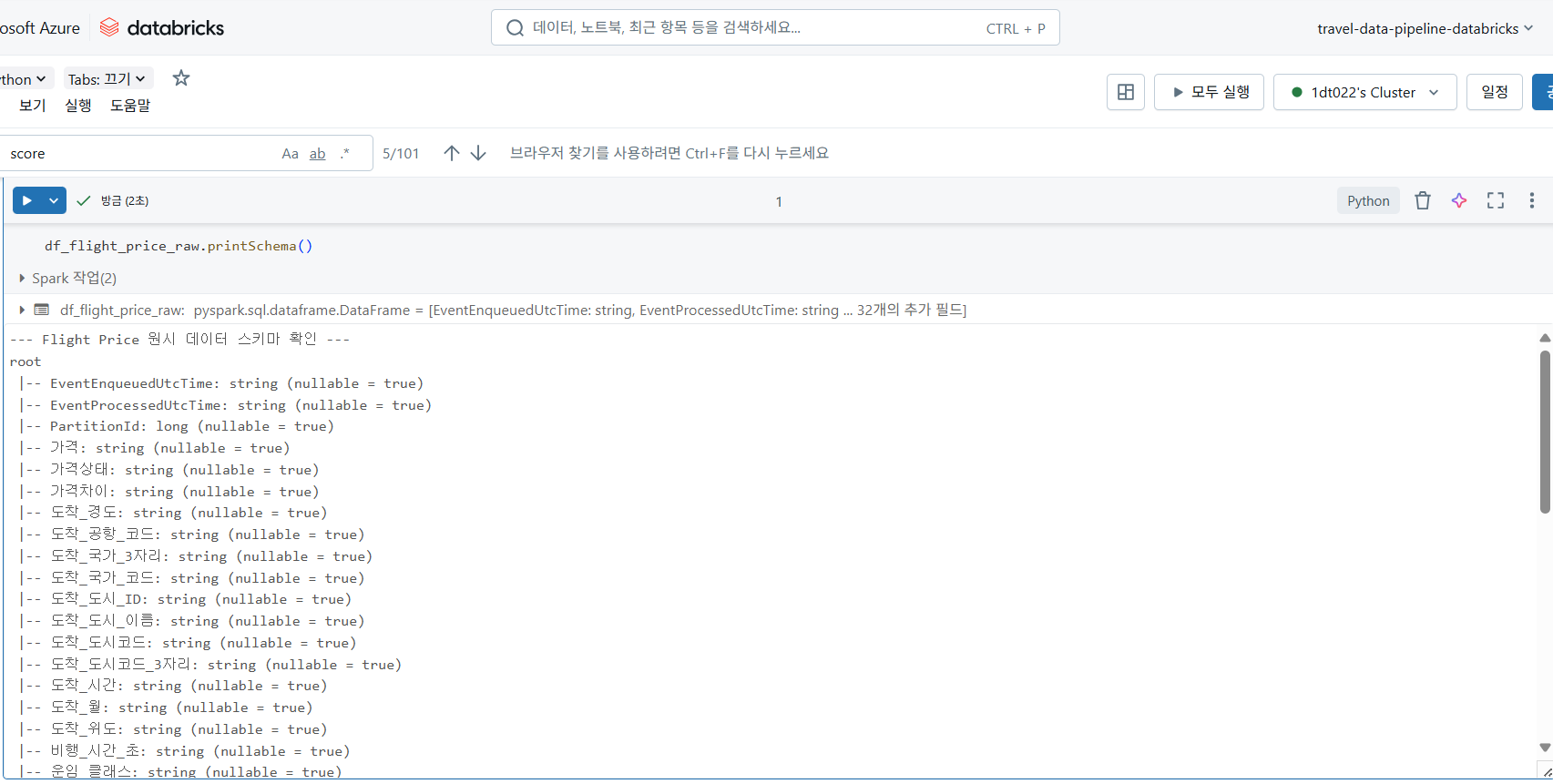
위 스키마에서 볼 수 있듯이, 가격, 평균가격, 비행시간과 같은 핵심 수치형 데이터가 string 타입으로 추론된 것을 확인할 수 있었다. 이는 데이터 연산에 앞서 반드시 타입 캐스팅이 필요함을 의미했다. 다른 데이터 소스들에서도 유사한 타입 불일치 및 컬럼명 비일관성 문제가 발견되었다.
4.2 데이터 품질 확보를 위한 전략적 접근
데이터를 버릴 수는 없었다. 우리는 데이터의 손실을 최소화하면서도 최대한의 정보를 활용할 수 있는 전략을 고민했다.
4.2.1 표준화된 매핑 테이블 구축
- 가장 시급했던 것은 중구난방인 국가 및 도시 이름을 통일하는 것이었다. 나는 전 세계 국가 및 도시가 표준화된 코드와 이름으로 매핑된 JSON 파일을 직접 생성했다. 이 매핑은 단순히 데이터 처리 단계에서 조인하는 것을 넘어, 초기 데이터 수집 단계(Azure Functions 크롤링 모듈)부터 적용되었다. 즉, 각 데이터 소스에서 데이터를 수집할 때부터 이 표준 매핑 테이블을 기반으로
iso_alpha3,country_korean_name과 같은 표준화된 컬럼을 추가적으로 수집하도록 파이프라인을 개선했다. 이로써 Databricks로 넘어오는 데이터는 초기보다 일관된 형식으로 들어올 수 있었고, 이는 데이터 통합 작업의 효율성을 크게 높였다.4.2.2 유연한 결합:
Left Outer Join채택 Inner Join이 데이터 손실을 야기한다는 것을 확인한 후, 우리는Left Outer Join을 적극적으로 활용하기로 결정했다. 기준이 되는 데이터셋(예: 특정 기간의 비행 데이터)을 중심으로 다른 데이터셋(환율, 트렌드, 날씨 등)을 결합하여, 조인되지 않는 값이 있더라도 기준 데이터의 행을 보존할 수 있도록 했다. 이로써 최대한 많은 도시-국가-월 조합에 대한 데이터를 손실 없이 통합할 수 있었다.4.2.3 결측치 처리 전략: 시각화 목표에 집중
Left Outer Join의 결과로 발생한 많은 결측치(null 값)는 또 다른 문제였다. 하지만 우리는 프로젝트의 궁극적인 목표가 ‘사용자에게 직관적인 시각화를 통한 추천’이라는 점에 집중했다.- 만약 특정 데이터(예: 항공권 정보)가 없는 경우, Power BI 대시보드에서 이를 ‘정보 없음’ 등으로 직관적으로 표시하면 된다고 판단했다.
- 매력도 점수 계산을 위한 결측치 처리: 특정 피처의 데이터가 없는 경우, 이를 합리적으로 점수에 반영해야 했다. 우리는 이러한 결측치에 0점 또는 마이너스 점수를 부여하여, 해당 정보가 없거나 불완전한 경우 전체 매력도 점수가 낮아지도록 설계했다. 이는 데이터가 없는 것도 하나의 ‘불리한 조건’으로 반영하여 최종 추천의 신뢰성을 유지하는 방법이었다.
4.3 Databricks에서의 핵심 처리 로직 (PySpark)
이러한 전략적 판단을 바탕으로 Databricks에서 PySpark를 활용하여 다음과 같은 핵심 처리 로직을 구현했다.
4.3.1 초기 설정 및 데이터 로드
Blob Storage에서 JSON 형식의 원시 데이터를 Spark DataFrame으로 로드하고, 복잡한 타입 캐스팅 및 null, 빈 문자열 처리를 수행했다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, when, avg, coalesce, from_json, current_timestamp, to_date, to_timestamp, row_number, trim, min
from pyspark.sql.types import (
StructType, StructField, StringType, FloatType, DoubleType, LongType, IntegerType, TimestampType, MapType, BooleanType,
)
from pyspark.sql.window import Window
# Spark 세션 생성
spark = SparkSession.builder.appName("TravelAttractionScoreCalculator").getOrCreate()
# Azure Blob Storage 연결 설정 (보안 주의: 실제 키는 Databricks Secrets 등으로 관리)
STORAGE_ACCOUNT_NAME = "traveldatastorage"
STORAGE_ACCOUNT_KEY = "..." # 실제 키는 직접 노출하지 않음
spark.conf.set(f"fs.azure.account.key.{STORAGE_ACCOUNT_NAME}.blob.core.windows.net", STORAGE_ACCOUNT_KEY)
# 데이터 경로 정의
exchange_rate_path = f"wasbs://output-exchange-rate-events@{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
google_trends_path = f"wasbs://output-google-trends-events@{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
rainy_score_path = f"wasbs://output-rainy-score-events@{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
city_budget_path = f"wasbs://output-city-budget-events@{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
country_alert_path = f"wasbs://output-country-alert-events@{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
# 스키마 정의 (가장 핵심적이고 깔끔한 스키마만 간략히 보여주는 것이 좋음)
exchange_rate_schema = StructType([
StructField("currency_code", StringType(), True),
StructField("realtime_rate", DoubleType(), True),
StructField("exchange_rate_score", DoubleType(), True),
StructField("country_code_3", StringType(), True),
StructField("EventProcessedUtcTime", TimestampType(), True)
])
google_trends_schema = StructType([
StructField("keyword", StringType(), True),
StructField("country_code_3", StringType(), True),
StructField("final_trend_score", DoubleType(), True),
StructField("timestamp", TimestampType(), True),
StructField("EventProcessedUtcTime", TimestampType(), True)
])
# ... (나머지 스키마는 블로그에는 생략하거나 간략화) ...
# 데이터 로드
df_exchange_rate = spark.read.schema(exchange_rate_schema).json(exchange_rate_path)
df_google_trends = spark.read.schema(google_trends_schema).json(google_trends_path)
# ... (나머지 DataFrame 로드) ...
4.3.2 데이터 정제 및 표준화 (예시: 환율 데이터)
# 환율 데이터 표준화 및 최종 스코어 컬럼 선택
df_exchange_rate_standard = df_exchange_rate.select(
col("country_code_3").alias("country_code"), # 조인 키 표준화
col("currency_code"),
col("EventProcessedUtcTime").alias("exchange_rate_processed_time"),
coalesce(
when(col("exchange_rate_score").cast(StringType()) == "", lit(None))
.otherwise(col("exchange_rate_score").cast(DoubleType())), lit(0.0)
).alias("exchange_rate_score") # String -> Double 캐스팅 및 NULL/빈 문자열 시 0.0 처리
)
4.3.3 최신 데이터 추출
Window.partitionBy().orderBy().row_number()와 같은 Spark Window 함수를 활용하여 각 데이터셋(예: 특정 도시의 최신 날씨, 특정 국가의 최신 트렌드)에서 시간 기준으로 가장 최신 데이터를 추출했다. 이를 통해 항상 최신 정보를 기반으로 매력도 점수를 계산할 수 있었다.
# 환율 데이터 최신 레코드 선택
window_spec_currency = Window.partitionBy("currency_code", "country_code").orderBy(col("exchange_rate_processed_time").desc())
df_exchange_rate_latest = df_exchange_rate_standard.withColumn("row_num", row_number().over(window_spec_currency)).filter(col("row_num") == 1).drop("row_num")
# Google Trends 최신 레코드 선택
window_spec_trends = Window.partitionBy("keyword", "country_code").orderBy(col("google_trends_processed_time").desc())
df_google_trends_latest = df_google_trends_standard.withColumn("row_num", row_number().over(window_spec_trends)).filter(col("row_num") == 1).drop("row_num")
4.3.4 데이터 조인 및 최종 스코어 계산 전 Null 처리
각 피처별로 정제되고 점수가 계산된 데이터셋들을 통합했다. 데이터 손실을 방지하고 모든 기준 데이터를 보존하기 위해 Left Outer Join을 핵심적으로 활용했다. 조인 후 발생하는 null 값들은 해당 피처의 점수를 0점 또는 마이너스 점수로 처리하여 최종 매력도 점수에 반영되도록 했다. 이로써 정보의 부재도 하나의 평가 요소가 되었다.
# 도시-예산-날씨 데이터 통합 (Left Outer Join)
df_city_union = df_rainy_score_latest.join(
df_city_budget_latest,
on = ["city_code", "country_code"],
how = "left_outer"
)
df_city_union = df_city_union.select(
col("country_code"), col("country_name_kor"), col("country_name_eng"),
col("city_name_eng"), col("city_code"), col("month"),
col("weather_score"), col("total_mid"), col("mid_range_score")
)
# 국가별 데이터 통합 (Google Trends, 환율, 국가 경보 - Left Outer Join)
df_country_union = df_google_trends_latest.join(
df_exchange_rate_latest,
on=["country_code"],
how = "left_outer"
).join(
df_country_alert_latest,
on=["country_code"],
how="left_outer"
)
df_country_union = df_country_union.select(
col("country_code"), col("final_trend_score"), col("exchange_rate_score"),
col("safety_score"), col("alarm_lvl")
)
# 최종 데이터 통합 (모든 조인은 Left Outer Join으로 진행)
df_union = df_city_union.join(df_country_union, on=["country_code"], how="left_outer")
# 월별 항공권 데이터는 별도로 집계 후 최종 조인
df_flight_price_monthly = df_flight_price_base.groupBy( # df_flight_price_base 생성 로직은 생략
"city_code", "country_code", "month").agg(
avg("flight_price_score").alias("avg_monthly_flight_score"),
min("flight_price").alias("min_monthly_flight_price")
)
df_final_union = df_union.join(
df_flight_price_monthly,
on=["month", "city_code", "country_code"],
how = "left_outer"
)
# 최종 매력도 점수 계산 전 null 값 처리 (결측치 -> 0점 또는 특정 값으로 변환)
df_final_union_kill_null = df_final_union\
.withColumn("final_trend_score", coalesce(col("final_trend_score"), lit(0.0)))\
.withColumn("exchange_rate_score", coalesce(col("exchange_rate_score"), lit(0.0)))\
.withColumn("mid_range_score", coalesce(col("mid_range_score"), lit(0.0)))\
.withColumn("safety_score", coalesce(col("safety_score"), lit(0.0)))\
.withColumn("weather_score", coalesce(col("weather_score"), lit(0.0)))\
.withColumn("avg_monthly_flight_score",coalesce(col("avg_monthly_flight_score"), lit(0.0)))\
.withColumn("min_monthly_flight_price",coalesce(col("min_monthly_flight_price"), lit(0.0)))
4.3.5 다양한 데이터셋 통합 및 최종 매력도 점수 산출 (Left Outer Join 중심)
모든 점수 컬럼을 합산하거나 가중치를 적용하여 최종 ‘여행지 매력도 점수’를 계산했다.
# 각 피처별 가중치 정의
W_TREND = 0.10 # Google Trends
W_EXCHANGE = 0.15 # 환율
W_FLIGHT = 0.20 # 항공권
W_ALERT = 0.10 # 여행 안전 정보
W_MID_RANGE = 0.30 # 현지 물가 (Mid-range 예산)
W_RAINY = 0.15 # 강수량 (날씨)
# 최종 매력도 점수 계산 (모든 점수를 합산하여 가중치 적용)
df_final_union_score = df_final_union_kill_null.withColumn("total_attraction_score",
(col("final_trend_score") * W_TREND) +
(col("exchange_rate_score") * W_EXCHANGE) +
(col("avg_monthly_flight_score") * W_FLIGHT) +
(col("mid_range_score") * W_MID_RANGE) +
(col("safety_score") * W_ALERT) +
(col("weather_score") * W_RAINY)
)
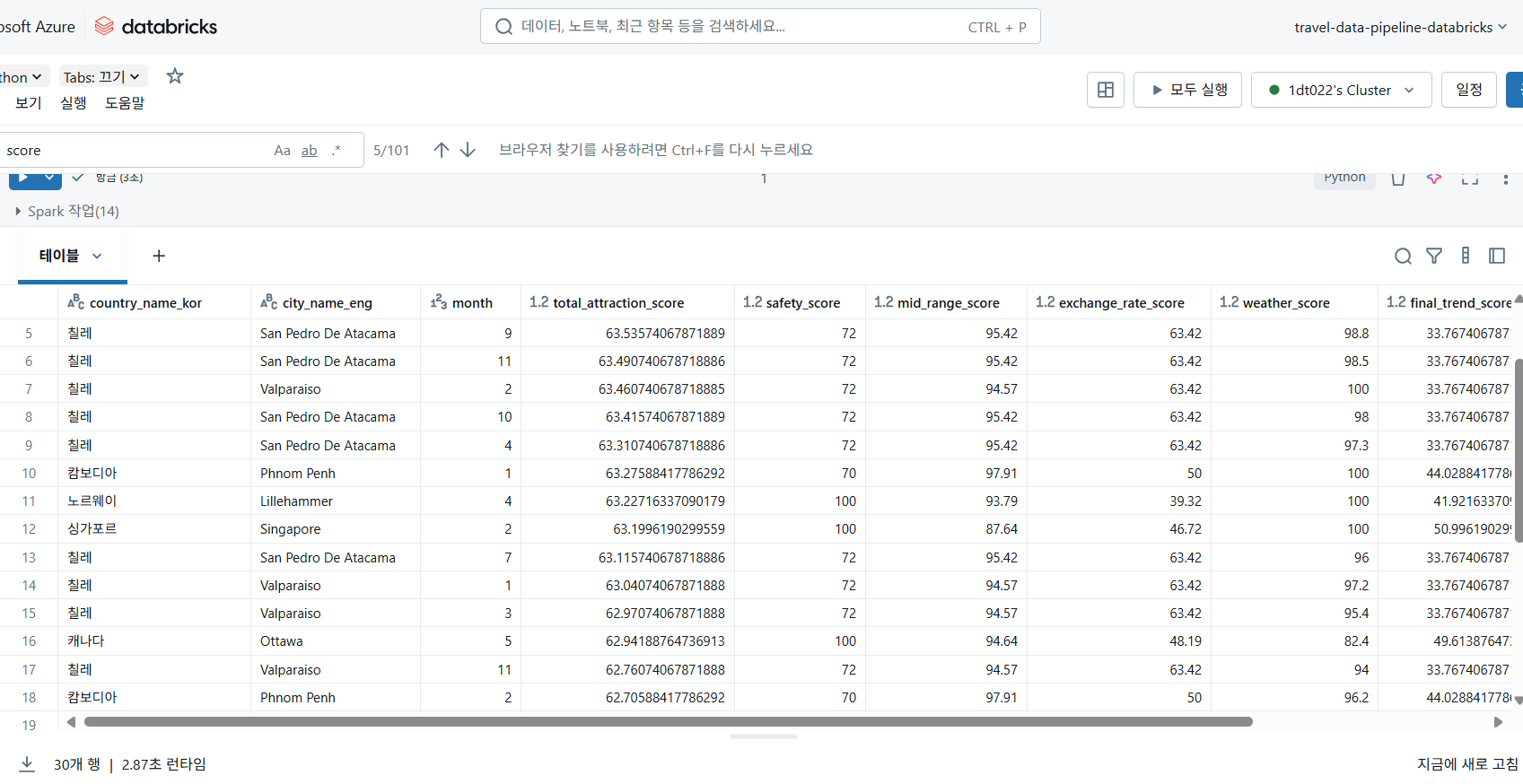
모든 데이터 정제, 통합 및 점수 계산 과정을 거쳐 최종적으로 위와 같은 여행지 매력도 점수 DataFrame을 생성했다. 이 DataFrame은 각 여행지의 종합 매력도 점수(total_attraction_score)와 개별 점수들을 포함한다.
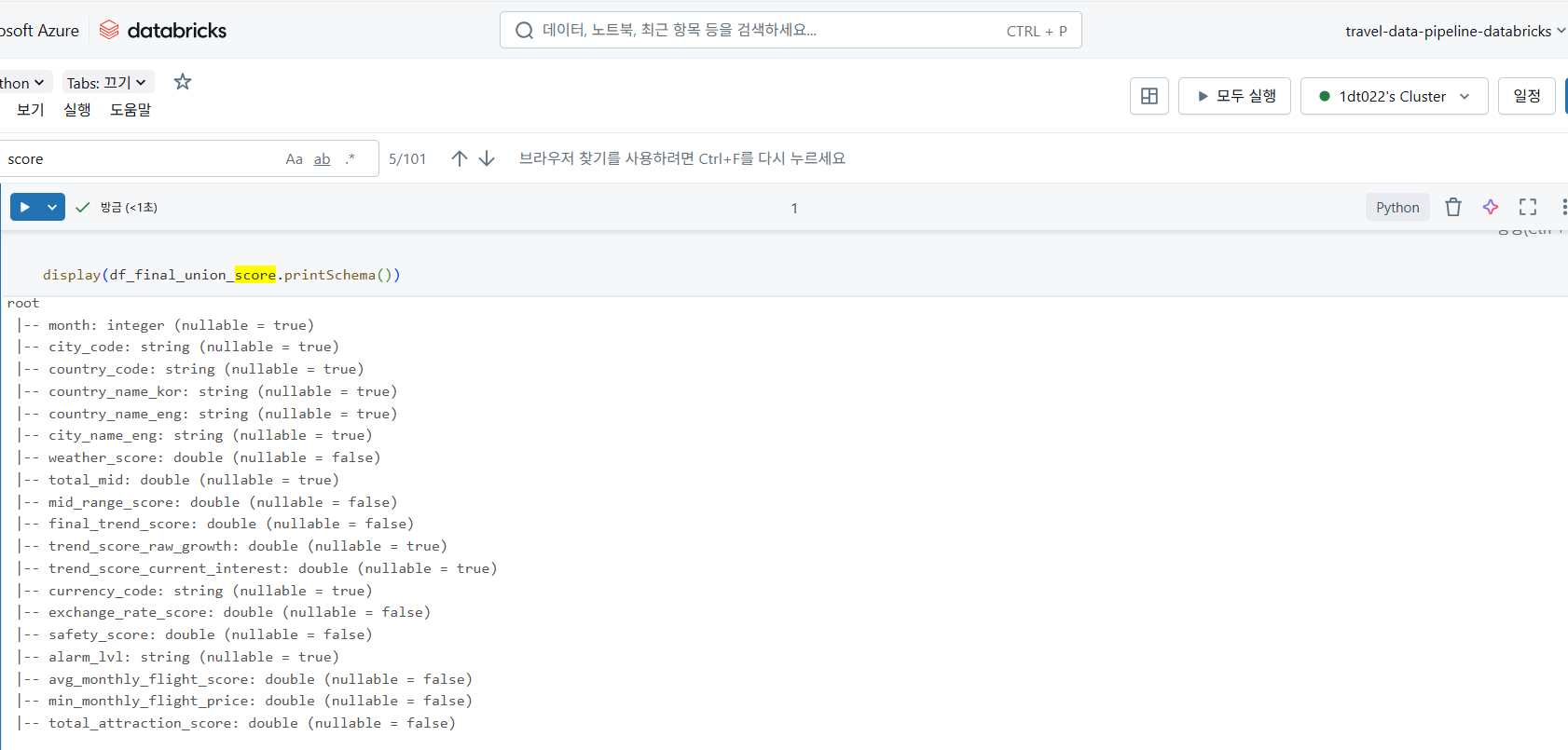
최종 DataFrame의 스키마를 확인하면, 모든 컬럼이 분석에 적합한 데이터 타입(예: double, integer)으로 깔끔하게 정리되었음을 알 수 있다.
4.4 데이터 웨어하우징: Unity Catalog에 Delta 테이블로 저장
이렇게 가공된 최종 매력도 점수 데이터는 Databricks의 Unity Catalog에 Delta 테이블 형식으로 저장되었다. Unity Catalog는 데이터 거버넌스와 보안을 중앙 집중화하여 데이터 자산 관리를 용이하게 했다. Delta Lake 형식은 데이터 레이크하우스 아키텍처의 핵심으로, 데이터 무결성(ACID 트랜잭션), 스키마 강제 적용, 변경 데이터 캡처(CDC), 시간 여행(Time Travel)과 같은 고급 기능을 제공하여 데이터의 신뢰성과 유연성을 크게 향상시켰다.
# 최종 DataFrame을 Unity Catalog에 Delta 테이블로 저장
table_name = "travel_data_pipeline_databricks.default.final_attraction_scores"
df_final_union_score.write.format("delta").mode("overwrite").saveAsTable(table_name)

Databricks Unity Catalog에 저장된 final_attraction_scores Delta 테이블의 데이터이다.
4.5 배치 처리 자동화: Databricks Job 활용
우리는 복잡한 배치 처리 과정을 Databricks Job을 활용하여 주기적으로 자동 실행되도록 설계했다. 이를 통해 수동 개입 없이도 최신 데이터를 기반으로 매력도 점수를 지속적으로 업데이트할 수 있었다.
5. Power BI: 데이터 시각화를 통한 인사이트 제공
이 모든 처리 과정을 거쳐 최종적으로 Power BI 대시보드를 통해 완성된 여행지 도시별 매력도 분석 결과를 시각화했다.
- 다양한 데이터 소스 연동: Azure Databricks에서 최종적으로 처리된 데이터와, Azure Stream Analytics에서 직접 스트리밍된 실시간 환율 및 날씨 데이터를 Power BI Desktop에서 연결했다.
- 직관적인 대시보드 구축: 데이터 모델링, 측정값 생성, 그리고 다양한 차트와 그래프(지도 시각화, 트렌드 라인 차트 등)를 활용하여 사용자가 ‘최적 여행지’를 쉽고 빠르게 파악할 수 있는 동적인 보고서를 구축했다.
- 대시보드 게시: 완성된 보고서는 Power BI Service에 게시하여 팀원 및 잠재적 사용자들과 공유했다. (대시보드 구성은 팀원들의 기여가 있었다.)
6. 앞으로의 이야기
Stream Analytics의 역할 재조정부터 Databricks를 통한 복잡한 데이터 통합 및 분석까지, 우리는 데이터 처리 파이프라인을 성공적으로 구축했다. 이 과정에서 각 클라우드 서비스의 특성과 더불어 실제 데이터의 ‘더러움’을 마주하고 이를 극복하며 유연하게 아키텍처를 진화시키는 값진 경험을 했다.
다음 포스팅에서는 프로젝트의 마지막 단계이자 가장 현실적인 난관이었던 클라우드 배포 과정에서 어떤 문제에 직면했으며, 그로부터 어떤 교훈을 얻었는지를 상세히 다룰 것이다. 또한, 프로젝트 전반에 대한 회고와 향후 개선 방안에 대해서도 이야기할 예정이다.