
[Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (4) : 클라우드 환경 운영 경험과 프로젝트 회고
'[Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기' 시리즈의 다른 글들
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (4) : 클라우드 환경 운영 경험과 프로젝트 회고 (현재 글)
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (3) : 아키텍처 변화와 데이터 처리 분석 (Stream Analytics ~ Databricks)
- [Microsoft Data School] 나만의 최적 여행지 추천 시스템 구축기 (2) : 데이터 수집 및 Google Trends HTTP 429 오류 해결
- [Azure 기반 End-to-End 데이터 파이프라인] 나만의 최적 여행지 추천 시스템 구축기(1) : 프로젝트 소개 및 아키텍처
지금까지 우리는 ‘나만의 최적 여행지 추천 시스템’ 프로젝트의 초기 비전부터 데이터 수집 과정에서의 HTTP 429 오류 해결, 그리고 복잡한 데이터 통합 및 아키텍처 진화 과정까지 살펴보았다. 모든 데이터 파이프라인의 핵심 기능은 성공적으로 구현되었고, 로컬 환경에서 안정적으로 작동함을 확인했다. 이번 포스팅에서는 클라우드 환경에서 이러한 파이프라인을 운영하고 관리하는 과정에서 얻은 경험과 중요한 교훈, 그리고 프로젝트 전반에 대한 솔직한 소회를 공유할 것이다.
1. 클라우드 환경에서의 파이프라인 운영 및 관리 경험
구축된 데이터 파이프라인의 핵심 구성 요소들은 모두 Microsoft Azure의 관리형 서비스로 구현되었다. 이 과정에서 클라우드 리소스를 효율적으로 사용하고 운영하는 경험을 쌓았다.
1.1 Azure Functions 및 클라우드 리소스 관리
Azure Functions(googleTrendsTrigger, googleTrendsProcessor, exchangeRateCrawler 등)를 포함한 데이터 수집 모듈은 로컬 환경에서 완벽하게 작동하여 안정적인 데이터 수집을 증명했다. 클라우드 환경에서 이러한 서버리스 함수를 관리하고, 다른 Azure 서비스들과 연동하는 과정은 클라우드 운영에 대한 실제 경험을 제공했다.
1.2 클라우드 리소스 연동 및 설정
Function App이 Event Hubs로 데이터를 전송하고, Stream Analytics가 Event Hubs에서 데이터를 받아 Blob Storage로 라우팅하며 Databricks가 Blob Storage의 데이터를 처리하는 등, 다양한 Azure 서비스 간의 연동 설정 및 관리 방법을 익혔다.
1.3 리소스 최적화 고려
클라우드 리소스를 효율적으로 사용하는 방법을 고민했다. 특히 사용량 기반으로 과금되는 서버리스 서비스의 특성을 이해하고, 불필요한 리소스 낭비를 줄이는 방향으로 설정을 최적화하는 경험을 했다.
2. 클라우드 환경 학습 및 주요 교훈
이러한 클라우드 환경에서의 파이프라인 운영 및 관리 경험을 통해 다음과 같은 중요한 교훈을 얻었다.
2.1 클라우드 리소스 관리의 복잡성 이해
다양한 Azure 서비스들의 복잡한 상호작용과 설정을 직접 다루면서 클라우드 환경이 제공하는 유연성과 함께, 이를 효율적으로 관리하기 위한 깊이 있는 이해가 필요함을 체감했다.
2.2 권한 및 보안 설정의 중요성
클라우드 서비스 간의 안전한 통신을 위한 권한 설정(IAM, Managed Identities 등)의 중요성을 학습했다. 이는 데이터 파이프라인의 보안과 안정성에 직결되는 핵심 요소임을 인지했다.
2.3 비용 효율적인 아키텍처 설계:
각 클라우드 서비스의 과금 체계를 이해하고, 비용을 최적화할 수 있는 아키텍처 패턴(예: 서버리스, 필요시 클러스터 활성화)을 적용하는 것이 중요함을 깨달았다.
3. 프로젝트 회고 및 개선 방안
‘나만의 최적 여행지 추천 시스템’ 프로젝트는 3주간의 Microsoft Data School 과정을 통해 많은 것을 배우고 경험할 수 있는 기회였다.
3.1 프로젝트 성과 요약
3.1.1 End-to-End 데이터 파이프라인 핵심 구축
Azure Functions, Event Hubs, Stream Analytics, Blob Storage, Databricks, Power BI를 활용하여 데이터 수집부터 처리, 저장, 시각화까지 이르는 핵심 구성 요소를 성공적으로 구현했다.
3.1.2 복잡한 문제 해결 능력 발휘
Google Trends HTTP 429 오류를 생산자-소비자 패턴 기반의 분산 처리 아키텍처로 극복하고, 원시 데이터의 품질 문제를 파악하여 표준 매핑, Left Outer Join, 결측치 처리 전략으로 해결하는 등 심층적인 문제 해결 능력을 발휘했다.
3.1.3 클라우드 서비스 이해도 증진
각 Azure 서비스의 특성(ASA의 실시간 처리 강점과 배치 처리 한계 등)을 깊이 이해하고, 이에 맞춰 아키텍처를 유연하게 진화시키는 경험을 했다.
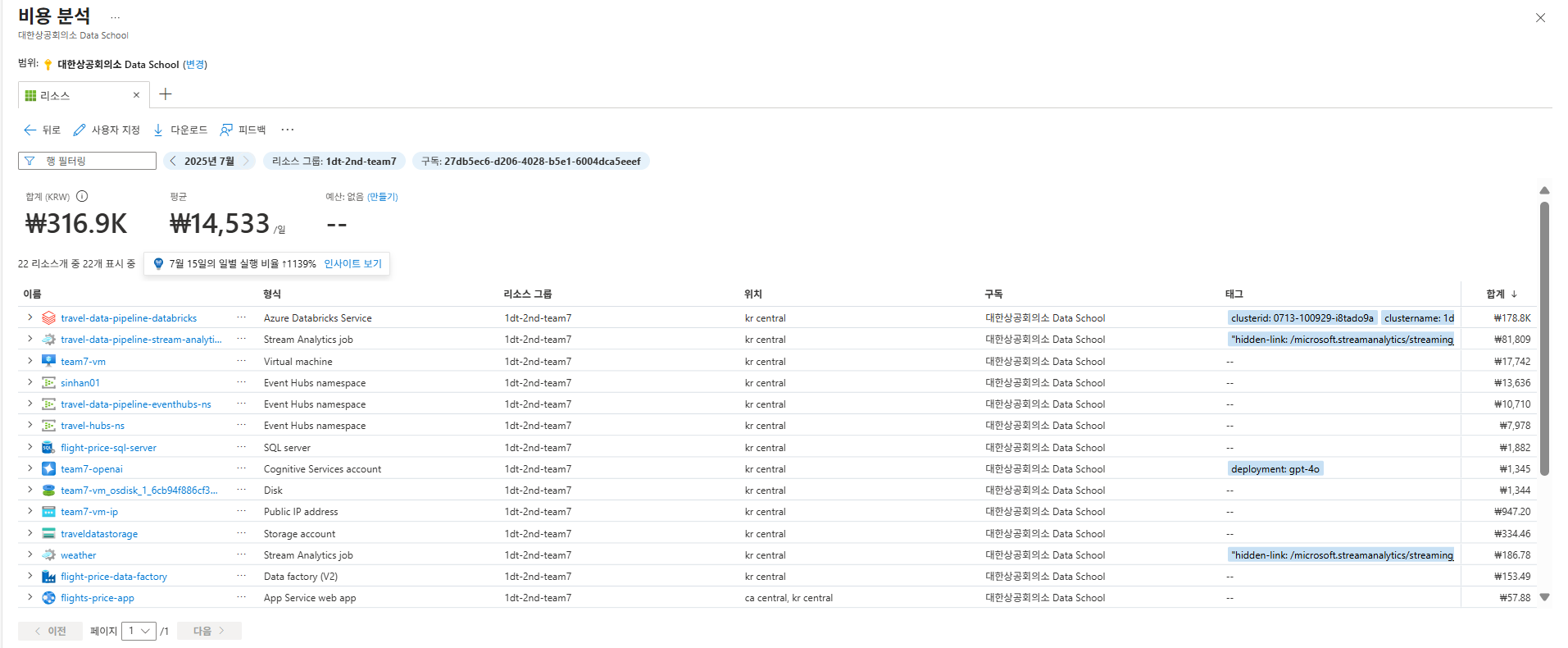
3.2 클라우드 리소스 사용 및 비용 효율성
이번 프로젝트에 할당된 Azure 예산은 약 150만원이었다. 약 3주간의 프로젝트 기간 동안 실제로 사용된 리소스 비용은 약 30만원 수준이었다. 이는 우리가 Azure의 PaaS(Platform as a Service) 서비스들을 적극적으로 활용하여 인프라 구축 및 관리에 소요되는 시간과 비용을 최소화했기 때문이다. Azure Functions, Event Hubs와 같이 사용량 기반으로 과금되는 서버리스 서비스를 최적화하고, Databricks 클러스터도 필요한 시점에만 활성화하고 작업 완료 후 종료하는 방식으로 운영 비용을 효율적으로 관리했다.
이 경험을 통해 클라우드 프로젝트에서 기술적 구현 능력뿐만 아니라, 비용 효율적인 아키텍처 설계와 리소스 관리 능력의 중요성을 깊이 체감했다. 이는 향후 실제 서비스 개발 및 운영 시 중요한 고려 사항이 될 것이다.
3.3 아쉬운 점 및 향후 개선 방안
프로젝트 전반적으로 긍정적인 경험이었지만, 몇 가지 아쉬운 점을 통해 중요한 교훈을 얻을 수 있었다.
3.3.1 초기 명세서 및 데이터 정의의 중요성
프로젝트 초반, 각 팀원들이 담당하는 데이터 수집 및 처리 부분에 대한 명세서와 데이터 정의(컬럼명, 데이터 타입, 형식 등)가 명확하게 이루어지지 않았던 점은 아쉬움 으로 남는다.
초반에는 팀 분위기가 좋았고 각자의 역할에 집중했지만, 이로 인해 데이터가 통합되는 Databricks 단계에서 컬럼명 불일치, 데이터 타입 혼재, 비일관적인 데이터 표현과 같은 예상치 못한 데이터 품질 문제에 직면했다.
이러한 문제들을 해결하는 데 많은 시간과 노력이 추가로 소요되었고, 이는 명확한 사전 정의와 지속적인 커뮤니케이션의 중요성을 절감하는 계기가 되었다. 향후 프로젝트에서는 초기 단계부터 데이터 거버넌스 원칙을 수립하고, 팀원 간의 데이터 인터페이스를 명확히 정의하는 것이 필수적이라고 생각한다.
3.3.2 자동화된 배포 및 CI/CD 구축
프로젝트 기간 내에는 모든 배포 과정을 완벽하게 자동화하지는 못했다. 향후 관리형 서비스 ID 및 Workload Identity Federation과 같은 현대적인 인증 방식을 적용하고, GitHub Actions 등의 CI/CD 파이프라인을 더욱 고도화하여 안전하고 효율적인 배포 시스템을 구축할 예정이다.
3.3.3 여행지 추천 시스템의 ‘매력도 점수’ 산출 로직 고도화
현재 점수 로직은 Rule-based이지만, 향후에는 머신러닝 모델(예: 회귀 모델, 랭킹 모델)을 도입하여 추천 정확도를 향상시키고, 추가적인 데이터 소스(예: 소셜 미디어 트렌드, 사용자 피드백)를 통합할 계획이다.
3.3.4 최종 사용자 웹 애플리케이션 개발:
현재 Power BI 대시보드 형태의 시각화에서 나아가, 사용자로부터 직접 선호도를 입력받고 추천 결과를 보여주는 완전한 웹 애플리케이션을 개발하여 서비스 사용성을 높일 것이다.
4. 결론
이번 Microsoft Data School 프로젝트는 클라우드 기반의 End-to-End 데이터 파이프라인을 직접 설계하고 구축하며 운영하는 전 과정에 참여할 수 있었던 소중한 경험이었다. 단순한 기술 학습을 넘어, 예상치 못한 문제에 대한 집요한 해결 과정과 현실적인 제약 속에서의 아키텍처 진화는 나에게 깊이 있는 통찰과 자신감을 주었다.
이 경험을 바탕으로 앞으로 더욱 복잡하고 도전적인 데이터 엔지니어링 프로젝트에 기여할 수 있는 역량을 갖추게 되었다고 생각한다.